TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data
Pengcheng Yin, Graham Neubig, Wen-tau Yih, Sebastian Riedel
Semantics: Sentence Level Long Paper
Session 14A: Jul 8
(17:00-18:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
Recent years have witnessed the burgeoning of pretrained language models (LMs) for text-based natural language (NL) understanding tasks. Such models are typically trained on free-form NL text, hence may not be suitable for tasks like semantic parsing over structured data, which require reasoning over both free-form NL questions and structured tabular data (e.g., database tables). In this paper we present TaBERT, a pretrained LM that jointly learns representations for NL sentences and (semi-)structured tables. TaBERT is trained on a large corpus of 26 million tables and their English contexts. In experiments, neural semantic parsers using TaBERT as feature representation layers achieve new best results on the challenging weakly-supervised semantic parsing benchmark WikiTableQuestions, while performing competitively on the text-to-SQL dataset Spider.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
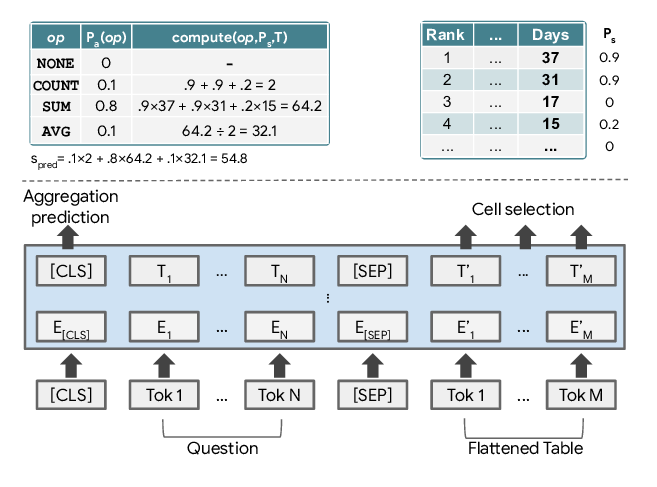
TaPas: Weakly Supervised Table Parsing via Pre-training
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, Julian Eisenschlos,
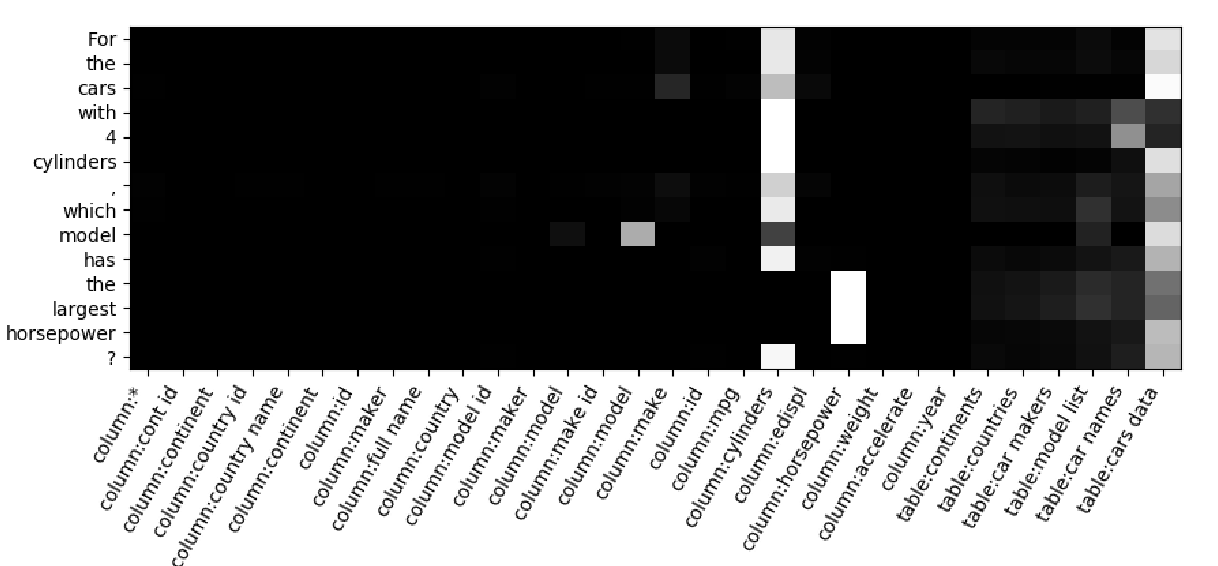
RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers
Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, Matthew Richardson,
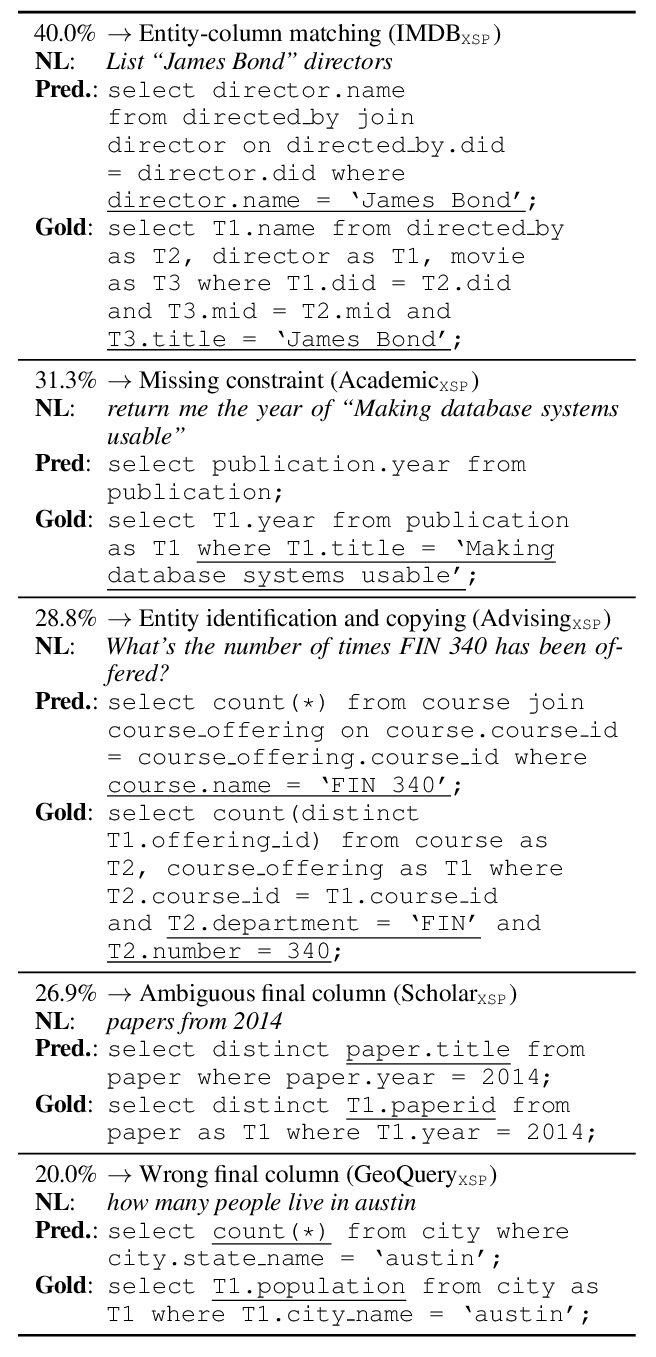
Exploring Unexplored Generalization Challenges for Cross-Database Semantic Parsing
Alane Suhr, Ming-Wei Chang, Peter Shaw, Kenton Lee,
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou,