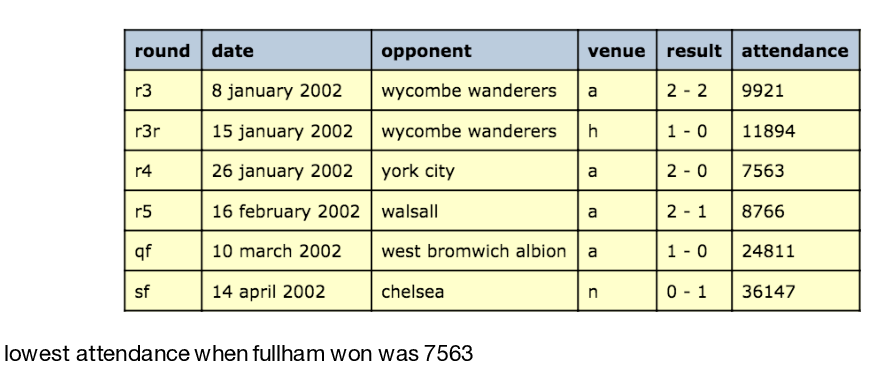
TaPas: Weakly Supervised Table Parsing via Pre-training
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, Julian Eisenschlos
Semantics: Sentence Level Long Paper
Session 7B: Jul 7
(09:00-10:00 GMT)

Session 8A: Jul 7
(12:00-13:00 GMT)
Abstract:
Answering natural language questions over tables is usually seen as a semantic parsing task. To alleviate the collection cost of full logical forms, one popular approach focuses on weak supervision consisting of denotations instead of logical forms. However, training semantic parsers from weak supervision poses difficulties, and in addition, the generated logical forms are only used as an intermediate step prior to retrieving the denotation. In this paper, we present TaPas, an approach to question answering over tables without generating logical forms. TaPas trains from weak supervision, and predicts the denotation by selecting table cells and optionally applying a corresponding aggregation operator to such selection. TaPas extends BERT's architecture to encode tables as input, initializes from an effective joint pre-training of text segments and tables crawled from Wikipedia, and is trained end-to-end. We experiment with three different semantic parsing datasets, and find that TaPas outperforms or rivals semantic parsing models by improving state-of-the-art accuracy on SQA from 55.1 to 67.2 and performing on par with the state-of-the-art on WikiSQL and WikiTQ, but with a simpler model architecture. We additionally find that transfer learning, which is trivial in our setting, from WikiSQL to WikiTQ, yields 48.7 accuracy, 4.2 points above the state-of-the-art.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data
Pengcheng Yin, Graham Neubig, Wen-tau Yih, Sebastian Riedel,

Unsupervised Dual Paraphrasing for Two-stage Semantic Parsing
Ruisheng Cao, Su Zhu, Chenyu Yang, Chen Liu, Rao Ma, Yanbin Zhao, Lu Chen, Kai Yu,
Span Selection Pre-training for Question Answering
Michael Glass, Alfio Gliozzo, Rishav Chakravarti, Anthony Ferritto, Lin Pan, G P Shrivatsa Bhargav, Dinesh Garg, Avi Sil,
Logical Natural Language Generation from Open-Domain Tables
Wenhu Chen, Jianshu Chen, Yu Su, Zhiyu Chen, William Yang Wang,