Revisiting Higher-Order Dependency Parsers
Erick Fonseca, André F. T. Martins
Syntax: Tagging, Chunking and Parsing Short Paper
Session 14B: Jul 8
(18:00-19:00 GMT)

Session 15B: Jul 8
(21:00-22:00 GMT)
Abstract:
Neural encoders have allowed dependency parsers to shift from higher-order structured models to simpler first-order ones, making decoding faster and still achieving better accuracy than non-neural parsers. This has led to a belief that neural encoders can implicitly encode structural constraints, such as siblings and grandparents in a tree. We tested this hypothesis and found that neural parsers may benefit from higher-order features, even when employing a powerful pre-trained encoder, such as BERT. While the gains of higher-order features are small in the presence of a powerful encoder, they are consistent for long-range dependencies and long sentences. In particular, higher-order models are more accurate on full sentence parses and on the exact match of modifier lists, indicating that they deal better with larger, more complex structures.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
TextBrewer: An Open-Source Knowledge Distillation Toolkit for Natural Language Processing
Ziqing Yang, Yiming Cui, Zhipeng Chen, Wanxiang Che, Ting Liu, Shijin Wang, Guoping Hu,

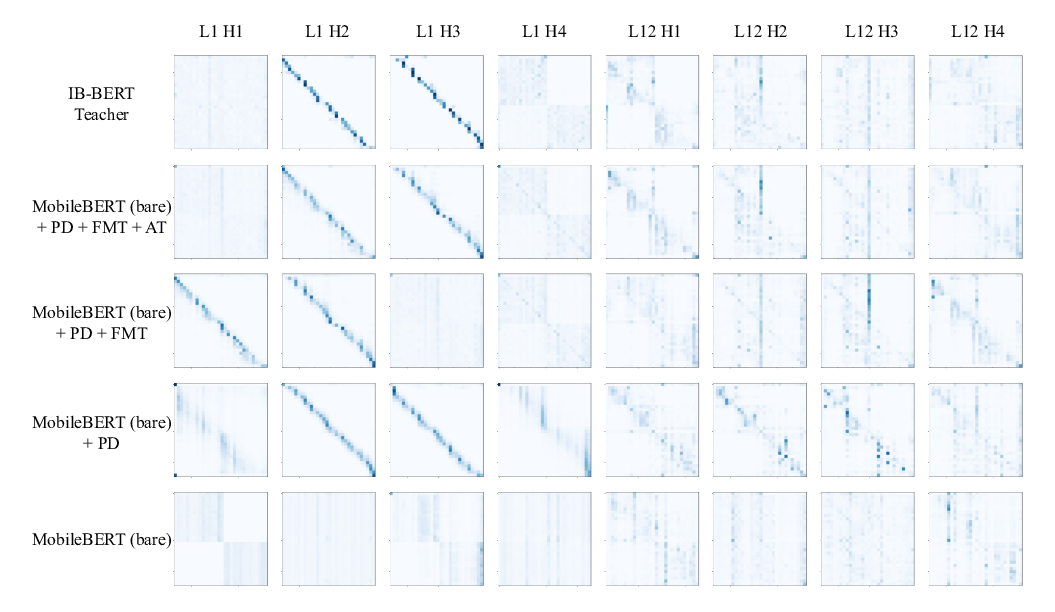
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou,