Injecting Numerical Reasoning Skills into Language Models
Mor Geva, Ankit Gupta, Jonathan Berant
Question Answering Long Paper
Session 1B: Jul 6
(06:00-07:00 GMT)

Session 2A: Jul 6
(08:00-09:00 GMT)
Abstract:
Large pre-trained language models (LMs) are known to encode substantial amounts of linguistic information. However, high-level reasoning skills, such as numerical reasoning, are difficult to learn from a language-modeling objective only. Consequently, existing models for numerical reasoning have used specialized architectures with limited flexibility. In this work, we show that numerical reasoning is amenable to automatic data generation, and thus one can inject this skill into pre-trained LMs, by generating large amounts of data, and training in a multi-task setup. We show that pre-training our model, GenBERT, on this data, dramatically improves performance on DROP (49.3 --> 72.3 F1), reaching performance that matches state-of-the-art models of comparable size, while using a simple and general-purpose encoder-decoder architecture. Moreover, GenBERT generalizes well to math word problem datasets, while maintaining high performance on standard RC tasks. Our approach provides a general recipe for injecting skills into large pre-trained LMs, whenever the skill is amenable to automatic data augmentation.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Span Selection Pre-training for Question Answering
Michael Glass, Alfio Gliozzo, Rishav Chakravarti, Anthony Ferritto, Lin Pan, G P Shrivatsa Bhargav, Dinesh Garg, Avi Sil,
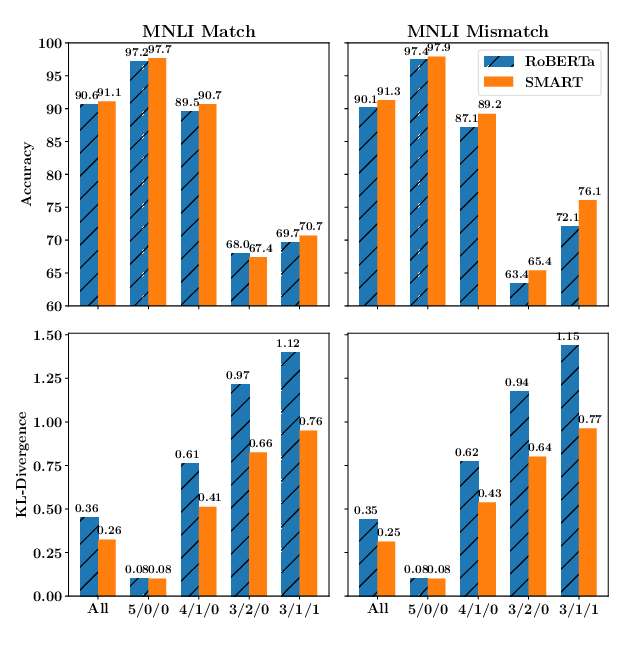
SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization
Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, Tuo Zhao,
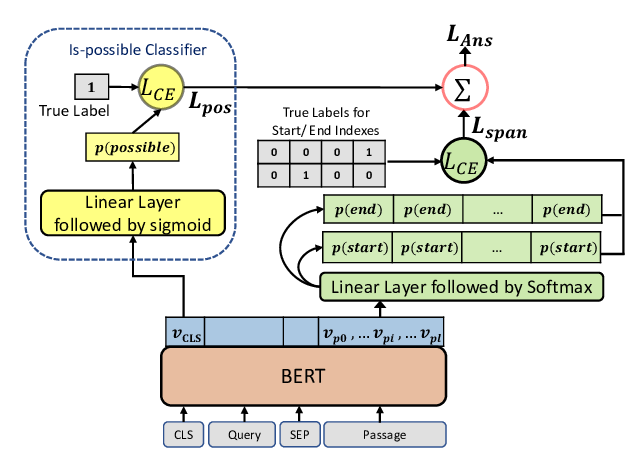
Pre-training Is (Almost) All You Need: An Application to Commonsense Reasoning
Alexandre Tamborrino, Nicola Pellicanò, Baptiste Pannier, Pascal Voitot, Louise Naudin,
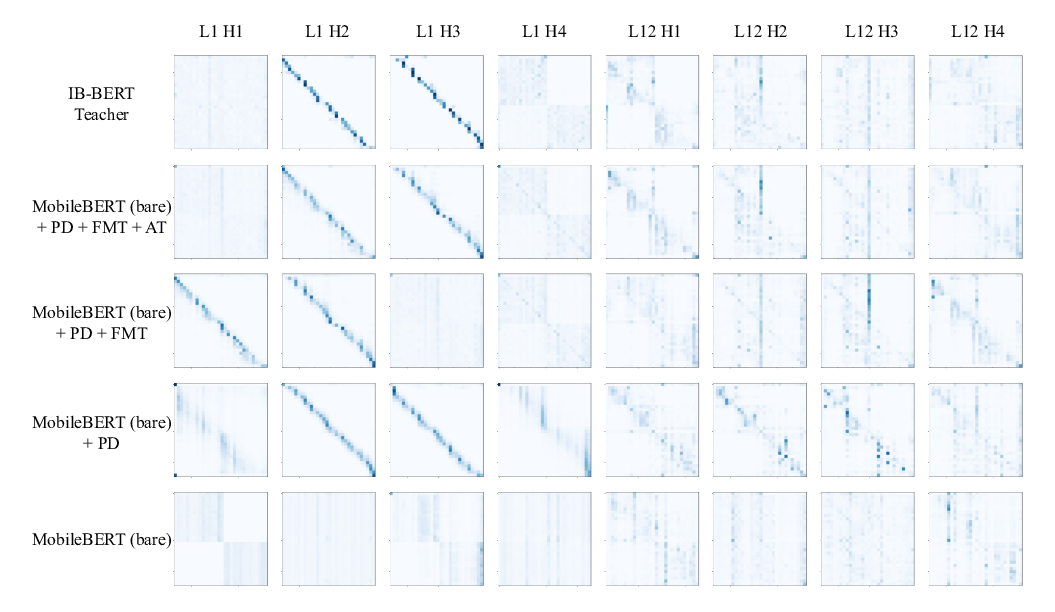
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou,