Moving Down the Long Tail of Word Sense Disambiguation with Gloss Informed Bi-encoders
Terra Blevins, Luke Zettlemoyer
Semantics: Lexical Long Paper
Session 1B: Jul 6
(06:00-07:00 GMT)

Session 4B: Jul 6
(18:00-19:00 GMT)
Abstract:
A major obstacle in Word Sense Disambiguation (WSD) is that word senses are not uniformly distributed, causing existing models to generally perform poorly on senses that are either rare or unseen during training. We propose a bi-encoder model that independently embeds (1) the target word with its surrounding context and (2) the dictionary definition, or gloss, of each sense. The encoders are jointly optimized in the same representation space, so that sense disambiguation can be performed by finding the nearest sense embedding for each target word embedding. Our system outperforms previous state-of-the-art models on English all-words WSD; these gains predominantly come from improved performance on rare senses, leading to a 31.1% error reduction on less frequent senses over prior work. This demonstrates that rare senses can be more effectively disambiguated by modeling their definitions.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multiple Languages
Tommaso Pasini, Federico Scozzafava, Bianca Scarlini,
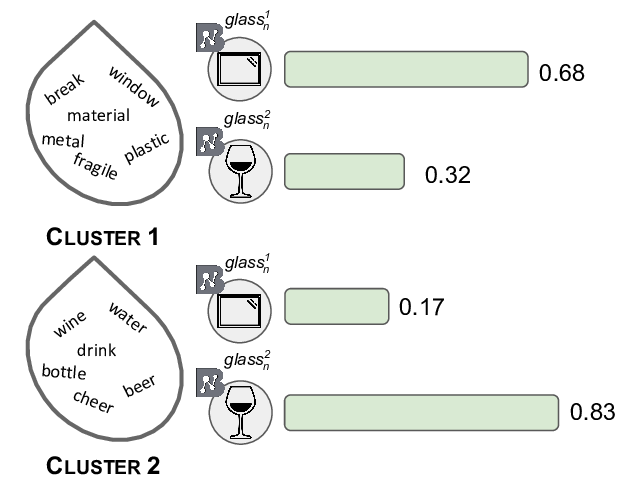
Breaking Through the 80% Glass Ceiling: Raising the State of the Art in Word Sense Disambiguation by Incorporating Knowledge Graph Information
Michele Bevilacqua, Roberto Navigli,
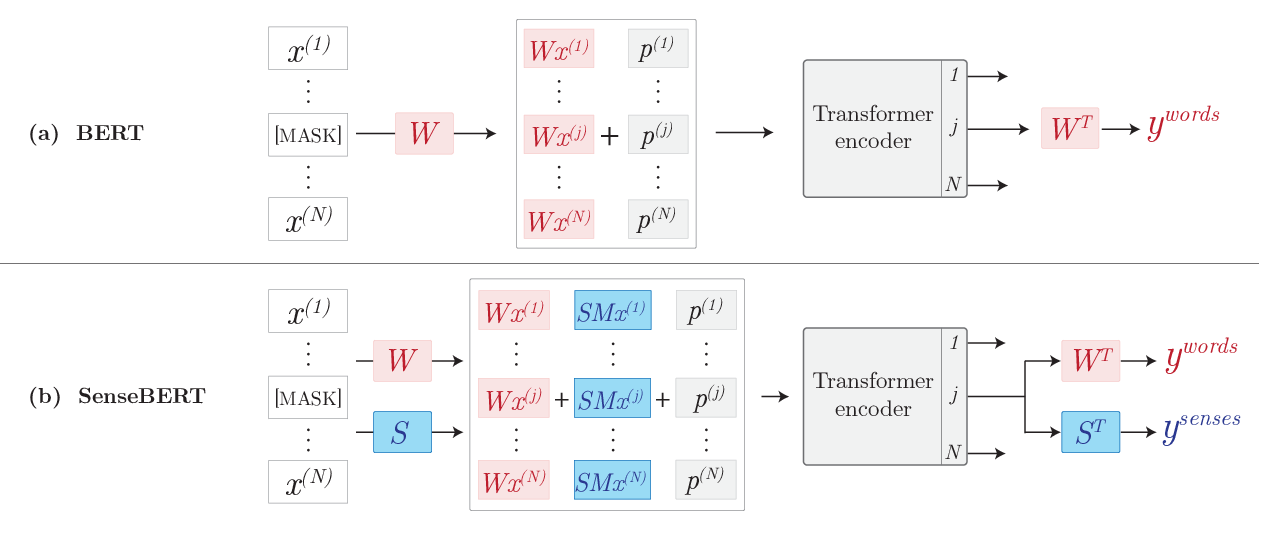
SenseBERT: Driving Some Sense into BERT
Yoav Levine, Barak Lenz, Or Dagan, Ori Ram, Dan Padnos, Or Sharir, Shai Shalev-Shwartz, Amnon Shashua, Yoav Shoham,
Coupling Distant Annotation and Adversarial Training for Cross-Domain Chinese Word Segmentation
Ning Ding, Dingkun Long, Guangwei Xu, Muhua Zhu, Pengjun Xie, Xiaobin Wang, Haitao Zheng,