Deep Contextualized Self-training for Low Resource Dependency Parsing
Guy Rotman, Roi Reichart
Syntax: Tagging, Chunking and Parsing TACL Paper
Session 14B: Jul 8
(18:00-19:00 GMT)

Session 15B: Jul 8
(21:00-22:00 GMT)
Abstract:
Neural dependency parsing has proven very effective, achieving state-of-the-art results on numerous domains and languages. Unfortunately, it requires large amounts of labeled data, that is costly and laborious to create. In this paper we propose a self-training algorithm that alleviates this annotation bottleneck by training a parser on its own output. Our Deep Contextualized Selftraining (DCST) algorithm utilizes representation models trained on sequence labeling tasks that are derived from the parser’s output when applied to unlabeled data, and integrates these models with the base parserthrough a gating mechanism. We conduct experiments across multiple languages, both in low resource in-domain and in cross-domain setups, and demonstrate that DCST substantially outperforms traditional self-training as well as recent semi-supervised training methods.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
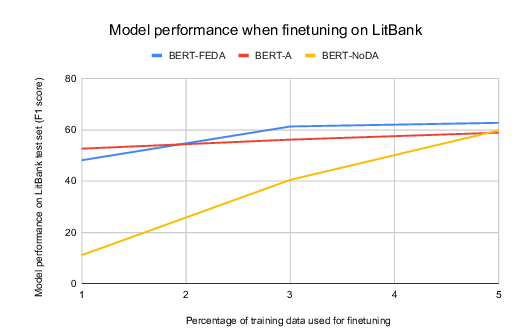
Improving Disfluency Detection by Self-Training a Self-Attentive Model
Paria Jamshid Lou, Mark Johnson,
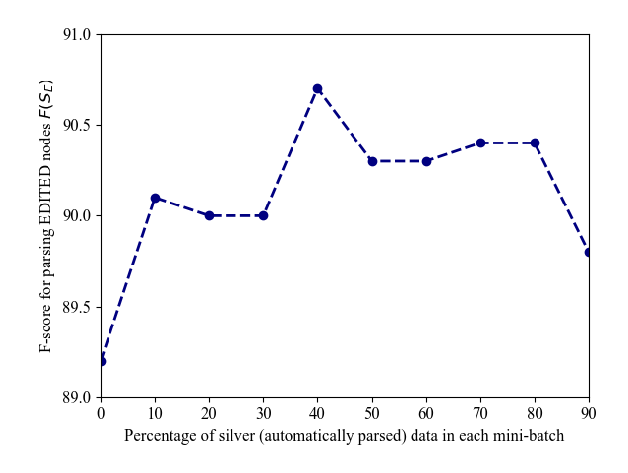
Zero-shot Text Classification via Reinforced Self-training
Zhiquan Ye, Yuxia Geng, Jiaoyan Chen, Jingmin Chen, Xiaoxiao Xu, Suhang Zheng, Feng Wang, Jun Zhang, Huajun Chen,
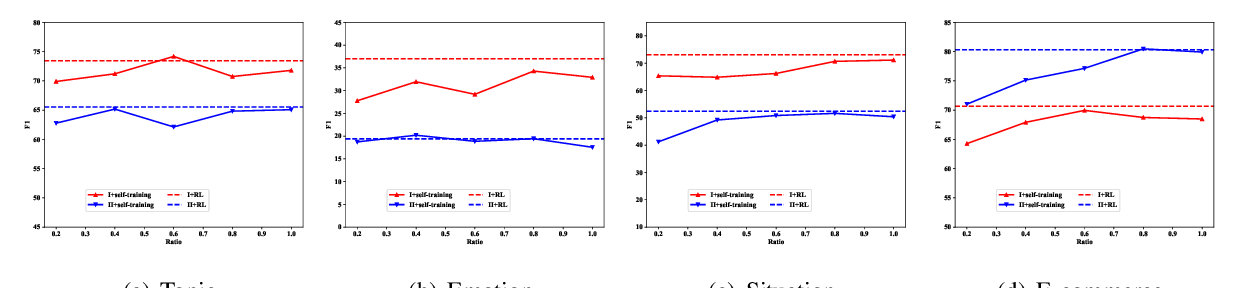
Adversarial and Domain-Aware BERT for Cross-Domain Sentiment Analysis
Chunning Du, Haifeng Sun, Jingyu Wang, Qi Qi, Jianxin Liao,
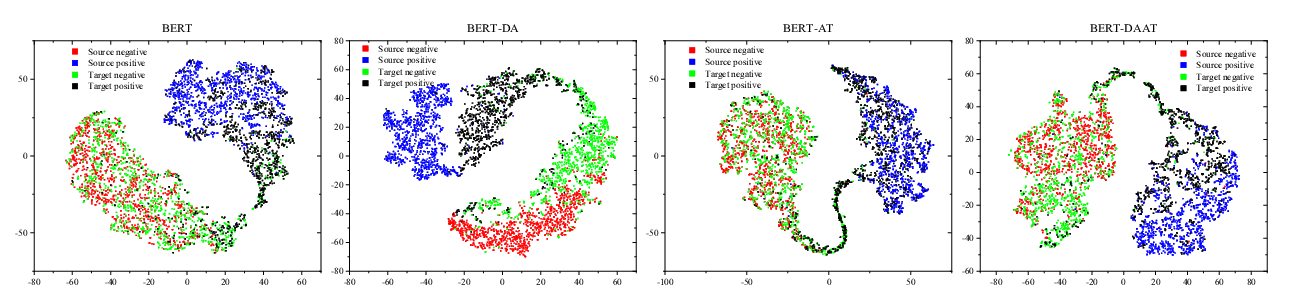
Towards Open Domain Event Trigger Identification using Adversarial Domain Adaptation
Aakanksha Naik, Carolyn Rose,