Will-They-Won't-They: A Very Large Dataset for Stance Detection on Twitter
Costanza Conforti, Jakob Berndt, Mohammad Taher Pilehvar, Chryssi Giannitsarou, Flavio Toxvaerd, Nigel Collier
Resources and Evaluation Short Paper
Session 2B: Jul 6
(09:00-10:00 GMT)

Session 3A: Jul 6
(12:00-13:00 GMT)
Abstract:
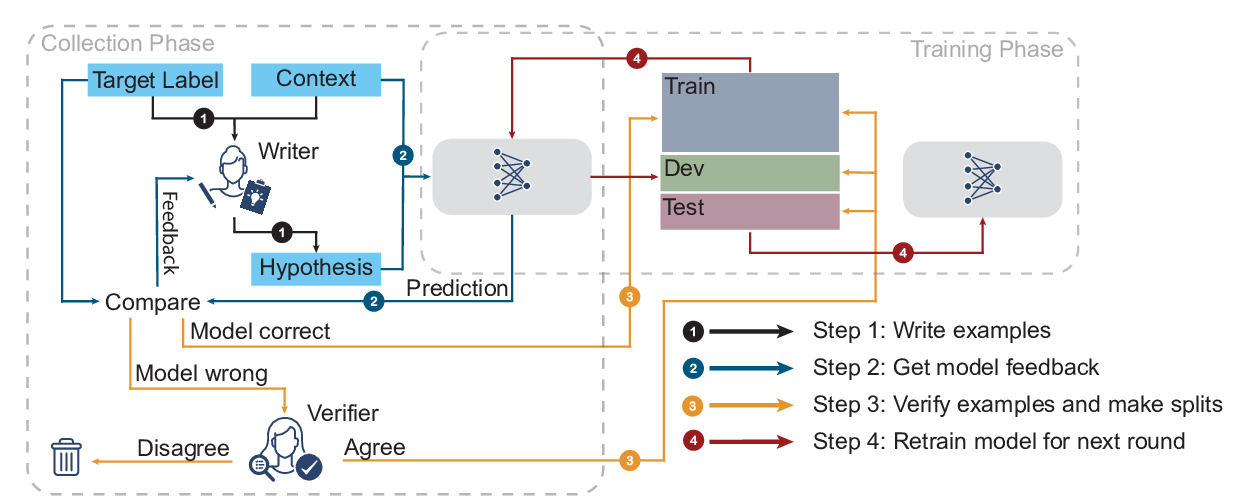
We present a new challenging stance detection dataset, called Will-They-Won’t-They (WT–WT), which contains 51,284 tweets in English, making it by far the largest available dataset of the type. All the annotations are carried out by experts; therefore, the dataset constitutes a high-quality and reliable benchmark for future research in stance detection. Our experiments with a wide range of recent state-of-the-art stance detection systems show that the dataset poses a strong challenge to existing models in this domain.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Enhancing Cross-target Stance Detection with Transferable Semantic-Emotion Knowledge
Bowen Zhang, Min Yang, Xutao Li, Yunming Ye, Xiaofei Xu, Kuai Dai,
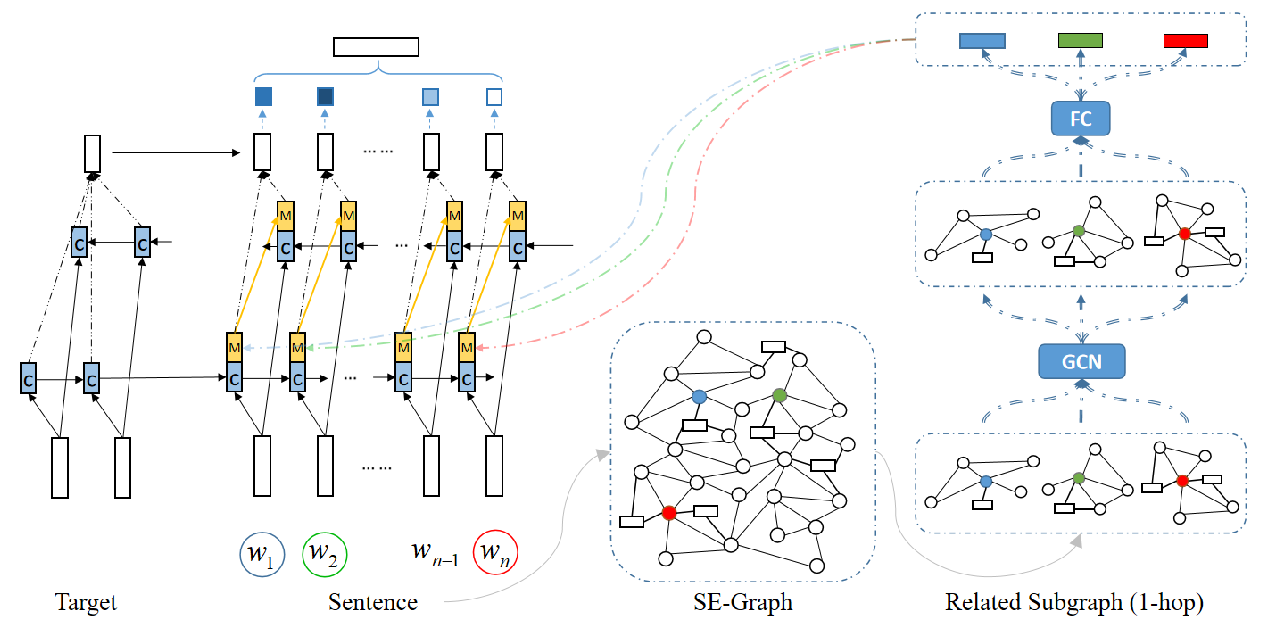
Agreement Prediction of Arguments in Cyber Argumentation for Detecting Stance Polarity and Intensity
Joseph Sirrianni, Xiaoqing Liu, Douglas Adams,
Dynamic Fusion Network for Multi-Domain End-to-end Task-Oriented Dialog
Libo Qin, Xiao Xu, Wanxiang Che, Yue Zhang, Ting Liu,
Adversarial NLI: A New Benchmark for Natural Language Understanding
Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, Douwe Kiela,