Generalizing Natural Language Analysis through Span-relation Representations
Zhengbao Jiang, Wei Xu, Jun Araki, Graham Neubig
Machine Learning for NLP Long Paper
Session 4A: Jul 6
(17:00-18:00 GMT)

Session 5A: Jul 6
(20:00-21:00 GMT)
Abstract:
Natural language processing covers a wide variety of tasks predicting syntax, semantics, and information content, and usually each type of output is generated with specially designed architectures. In this paper, we provide the simple insight that a great variety of tasks can be represented in a single unified format consisting of labeling spans and relations between spans, thus a single task-independent model can be used across different tasks. We perform extensive experiments to test this insight on 10 disparate tasks spanning dependency parsing (syntax), semantic role labeling (semantics), relation extraction (information content), aspect based sentiment analysis (sentiment), and many others, achieving performance comparable to state-of-the-art specialized models. We further demonstrate benefits of multi-task learning, and also show that the proposed method makes it easy to analyze differences and similarities in how the model handles different tasks. Finally, we convert these datasets into a unified format to build a benchmark, which provides a holistic testbed for evaluating future models for generalized natural language analysis.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
KLEJ: Comprehensive Benchmark for Polish Language Understanding
Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik,

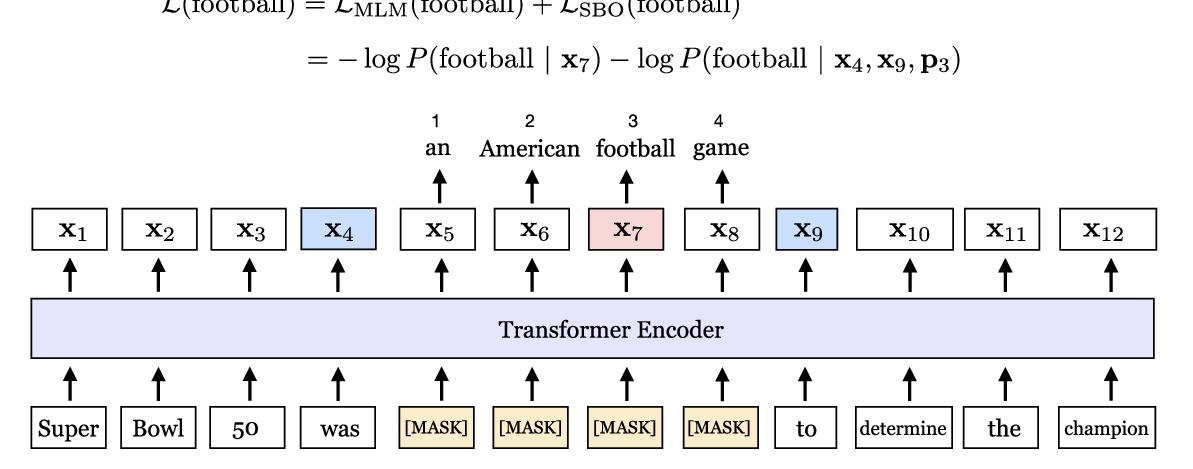
SpanBERT: Improving Pre-training by Representing and Predicting Spans
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, Omer Levy,
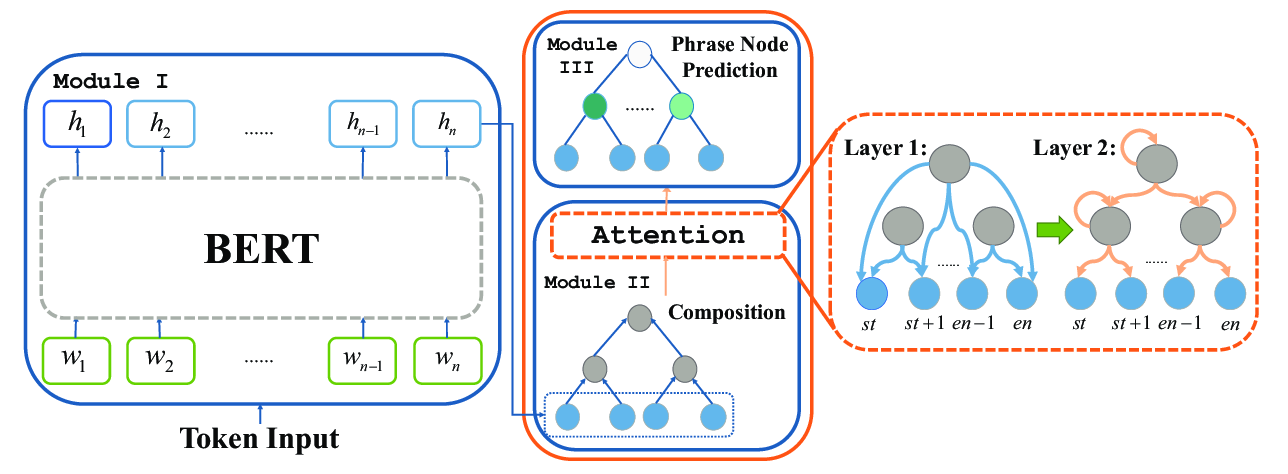
SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics
Da Yin, Tao Meng, Kai-Wei Chang,
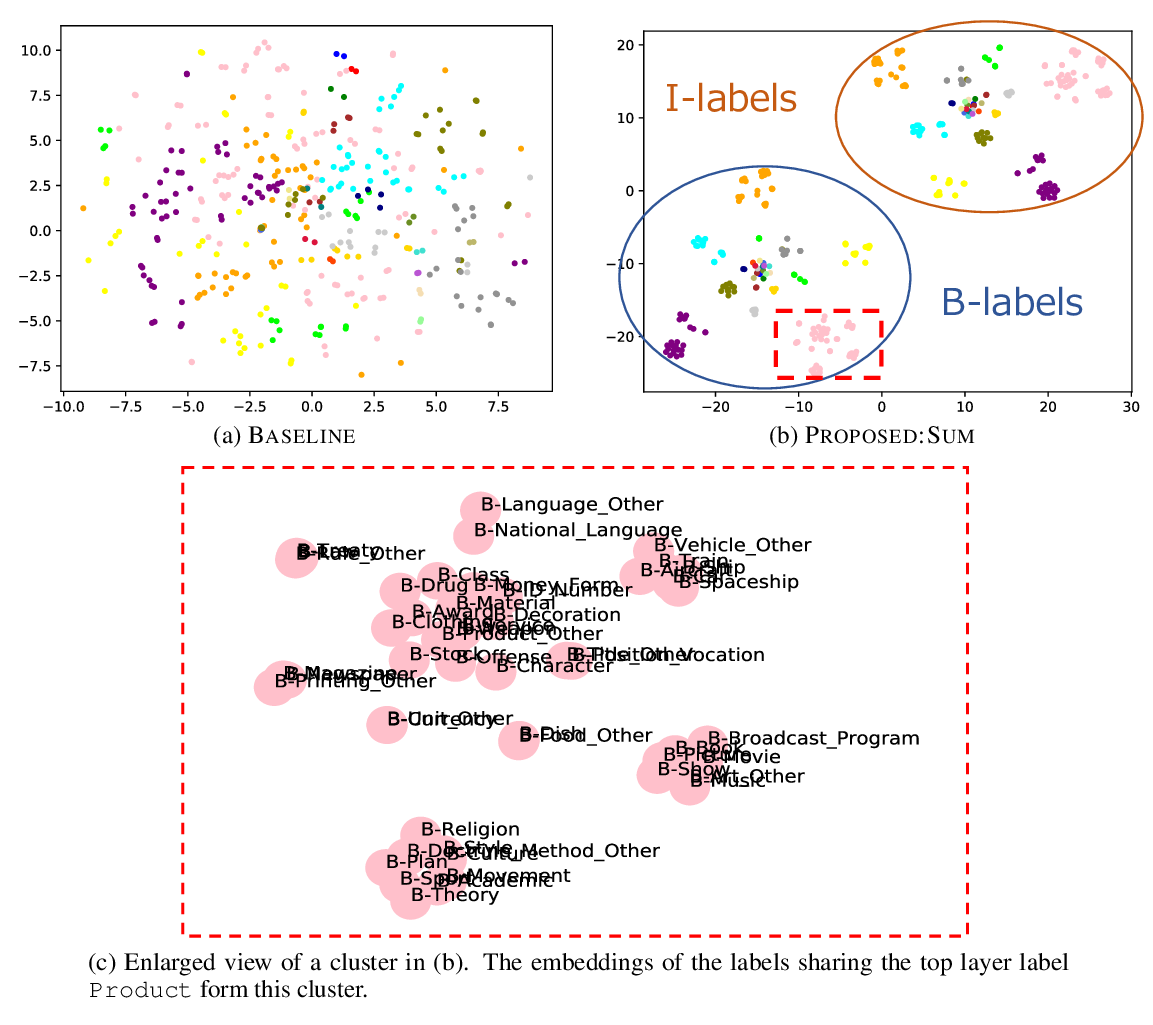
Embeddings of Label Components for Sequence Labeling: A Case Study of Fine-grained Named Entity Recognition
Takuma Kato, Kaori Abe, Hiroki Ouchi, Shumpei Miyawaki, Jun Suzuki, Kentaro Inui,