Efficient Strategies for Hierarchical Text Classification: External Knowledge and Auxiliary Tasks
Kervy Rivas Rojas, Gina Bustamante, Arturo Oncevay, Marco Antonio Sobrevilla Cabezudo
NLP Applications Short Paper
Session 4A: Jul 6
(17:00-18:00 GMT)

Session 5B: Jul 6
(21:00-22:00 GMT)
Abstract:
In hierarchical text classification, we perform a sequence of inference steps to predict the category of a document from top to bottom of a given class taxonomy. Most of the studies have focused on developing novels neural network architectures to deal with the hierarchical structure, but we prefer to look for efficient ways to strengthen a baseline model. We first define the task as a sequence-to-sequence problem. Afterwards, we propose an auxiliary synthetic task of bottom-up-classification. Then, from external dictionaries, we retrieve textual definitions for the classes of all the hierarchy's layers, and map them into the word vector space. We use the class-definition embeddings as an additional input to condition the prediction of the next layer and in an adapted beam search. Whereas the modified search did not provide large gains, the combination of the auxiliary task and the additional input of class-definitions significantly enhance the classification accuracy. With our efficient approaches, we outperform previous studies, using a drastically reduced number of parameters, in two well-known English datasets.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
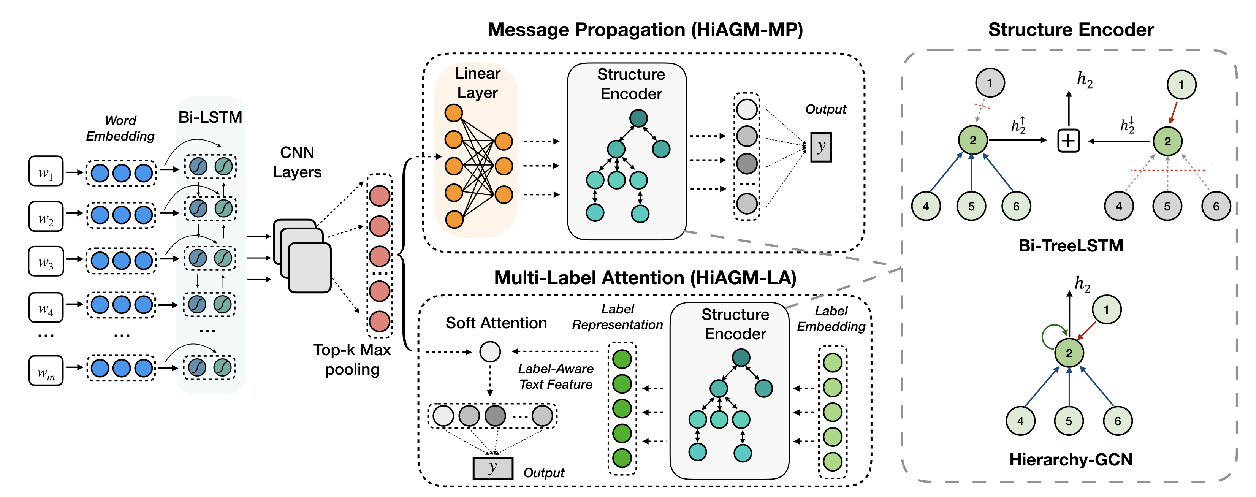
Hierarchy-Aware Global Model for Hierarchical Text Classification
Jie Zhou, Chunping Ma, Dingkun Long, Guangwei Xu, Ning Ding, Haoyu Zhang, Pengjun Xie, Gongshen Liu,
Modeling Label Semantics for Predicting Emotional Reactions
Radhika Gaonkar, Heeyoung Kwon, Mohaddeseh Bastan, Niranjan Balasubramanian, Nathanael Chambers,
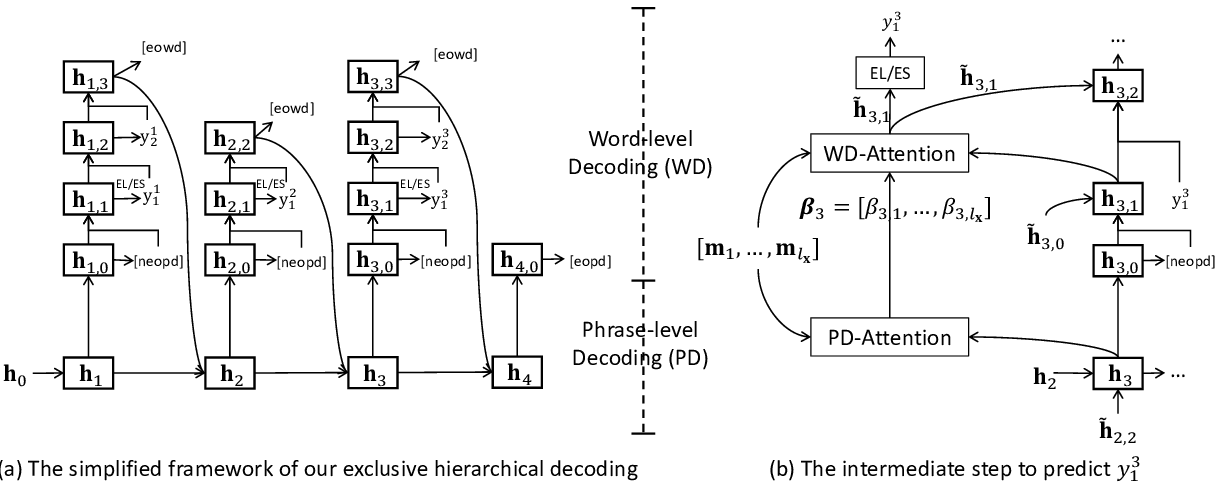
Exclusive Hierarchical Decoding for Deep Keyphrase Generation
Wang Chen, Hou Pong Chan, Piji Li, Irwin King,