Enabling Language Models to Fill in the Blanks
Chris Donahue, Mina Lee, Percy Liang
Generation Short Paper
Session 4B: Jul 6
(18:00-19:00 GMT)

Session 5A: Jul 6
(20:00-21:00 GMT)
Abstract:
We present a simple approach for text infilling, the task of predicting missing spans of text at any position in a document. While infilling could enable rich functionality especially for writing assistance tools, more attention has been devoted to language modeling---a special case of infilling where text is predicted at the end of a document. In this paper, we aim to extend the capabilities of language models (LMs) to the more general task of infilling. To this end, we train (or fine tune) off-the-shelf LMs on sequences containing the concatenation of artificially-masked text and the text which was masked. We show that this approach, which we call infilling by language modeling, can enable LMs to infill entire sentences effectively on three different domains: short stories, scientific abstracts, and lyrics. Furthermore, we show that humans have difficulty identifying sentences infilled by our approach as machine-generated in the domain of short stories.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Span-ConveRT: Few-shot Span Extraction for Dialog with Pretrained Conversational Representations
Samuel Coope, Tyler Farghly, Daniela Gerz, Ivan Vulić, Matthew Henderson,
A Knowledge-Enhanced Pretraining Model for Commonsense Story Generation
Jian Guan, Fei Huang, Minlie Huang, Zhihao Zhao, Xiaoyan Zhu,
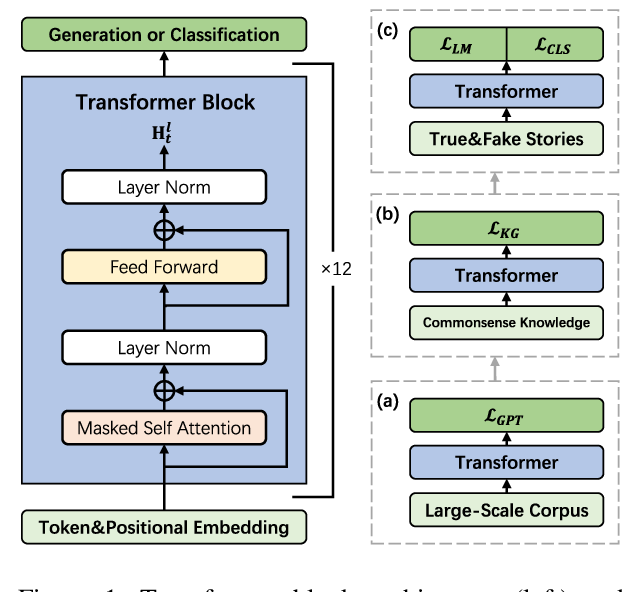
SpanBERT: Improving Pre-training by Representing and Predicting Spans
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, Omer Levy,
Reverse Engineering Configurations of Neural Text Generation Models
Yi Tay, Dara Bahri, Che Zheng, Clifford Brunk, Donald Metzler, Andrew Tomkins,