BabyWalk: Going Farther in Vision-and-Language Navigation by Taking Baby Steps
Wang Zhu, Hexiang Hu, Jiacheng Chen, Zhiwei Deng, Vihan Jain, Eugene Ie, Fei Sha
Language Grounding to Vision, Robotics and Beyond Long Paper
Session 4B: Jul 6
(18:00-19:00 GMT)

Session 5B: Jul 6
(21:00-22:00 GMT)
Abstract:
Learning to follow instructions is of fundamental importance to autonomous agents for vision-and-language navigation (VLN). In this paper, we study how an agent can navigate long paths when learning from a corpus that consists of shorter ones. We show that existing state-of-the-art agents do not generalize well. To this end, we propose BabyWalk, a new VLN agent that is learned to navigate by decomposing long instructions into shorter ones (BabySteps) and completing them sequentially. A special design memory buffer is used by the agent to turn its past experiences into contexts for future steps. The learning process is composed of two phases. In the first phase, the agent uses imitation learning from demonstration to accomplish BabySteps. In the second phase, the agent uses curriculum-based reinforcement learning to maximize rewards on navigation tasks with increasingly longer instructions. We create two new benchmark datasets (of long navigation tasks) and use them in conjunction with existing ones to examine BabyWalk's generalization ability. Empirical results show that BabyWalk achieves state-of-the-art results on several metrics, in particular, is able to follow long instructions better. The codes and the datasets are released on our project page: https://github.com/Sha-Lab/babywalk.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
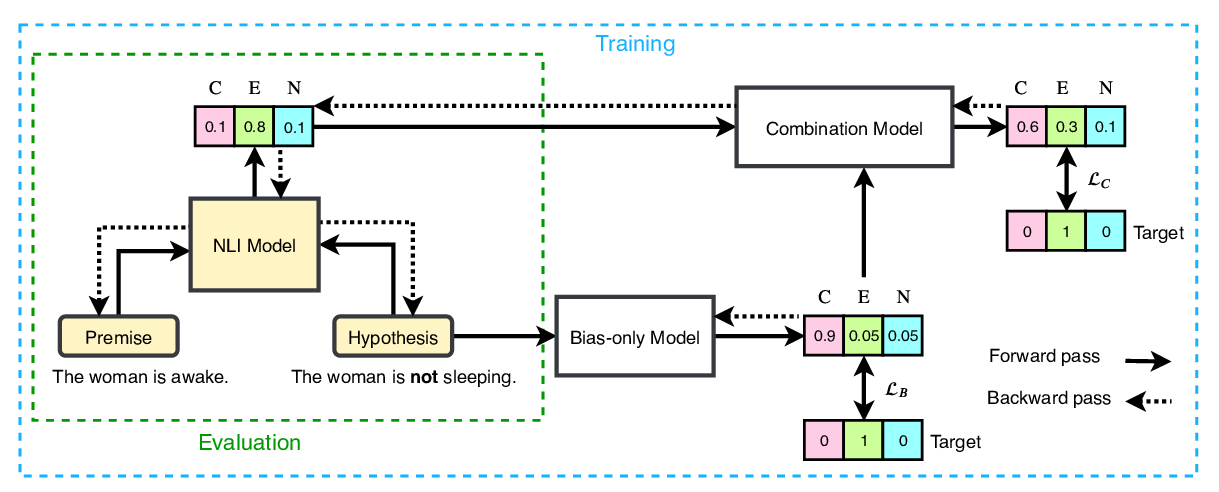
End-to-End Bias Mitigation by Modelling Biases in Corpora
Rabeeh Karimi Mahabadi, Yonatan Belinkov, James Henderson,
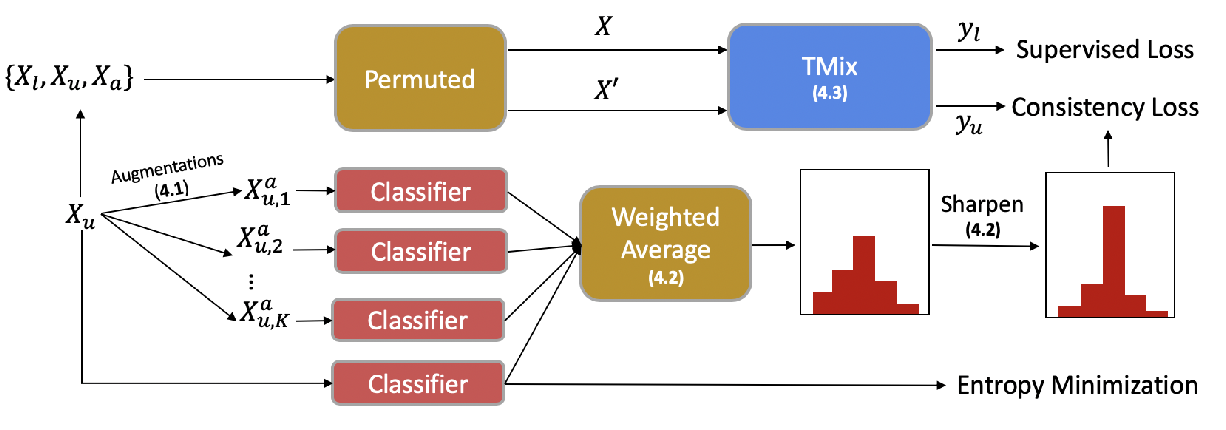
MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
Jiaao Chen, Zichao Yang, Diyi Yang,
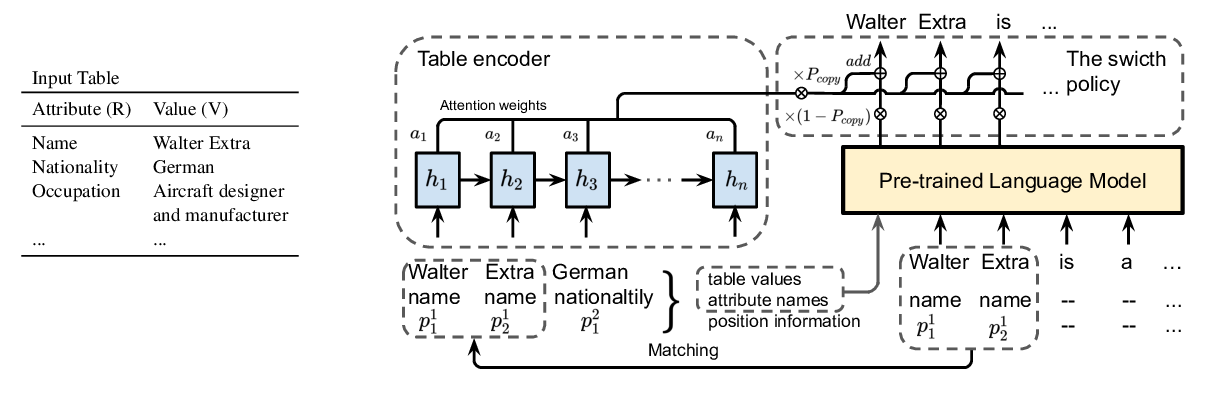
Few-Shot NLG with Pre-Trained Language Model
Zhiyu Chen, Harini Eavani, Wenhu Chen, Yinyin Liu, William Yang Wang,
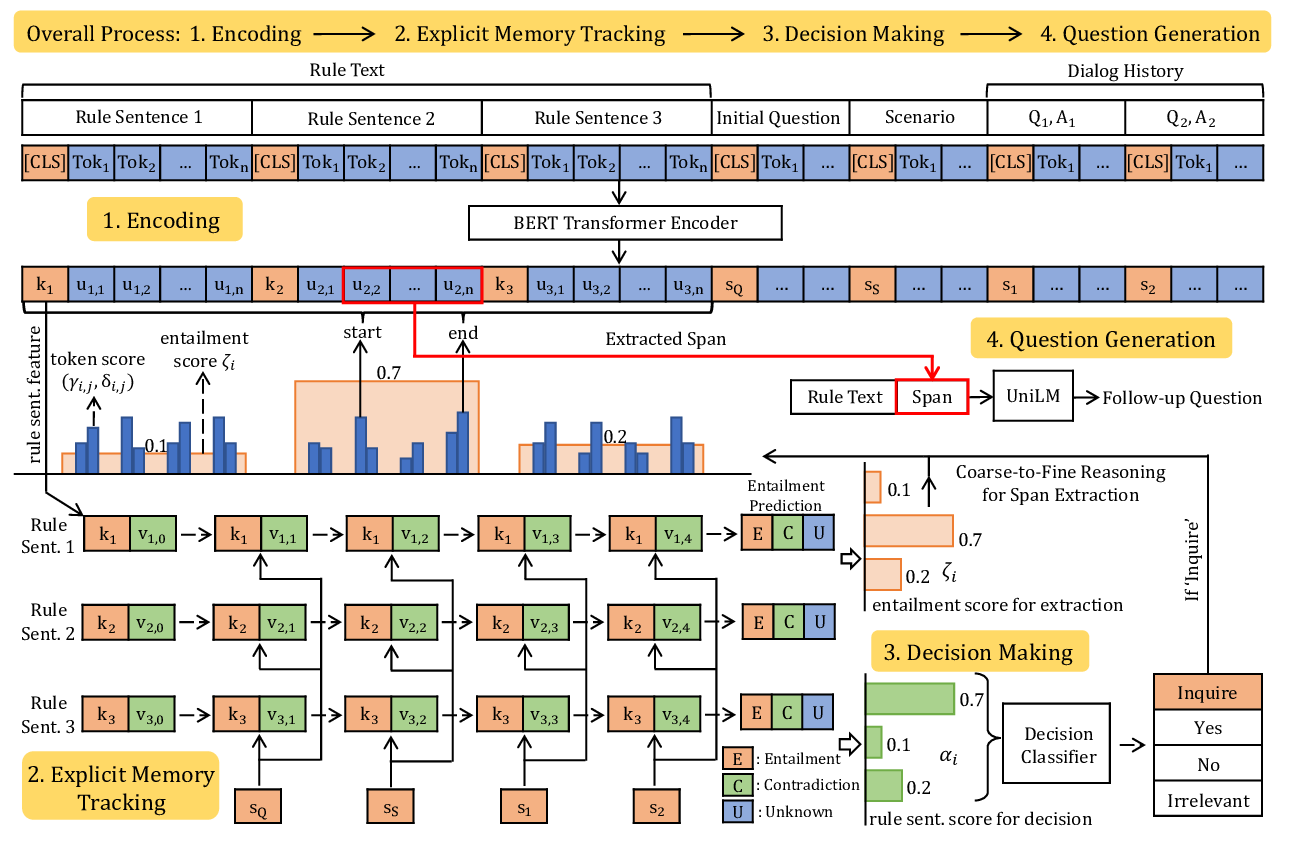
Explicit Memory Tracker with Coarse-to-Fine Reasoning for Conversational Machine Reading
Yifan Gao, Chien-Sheng Wu, Shafiq Joty, Caiming Xiong, Richard Socher, Irwin King, Michael Lyu, Steven C.H. Hoi,