MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning
Jie Lei, Liwei Wang, Yelong Shen, Dong Yu, Tamara Berg, Mohit Bansal
Language Grounding to Vision, Robotics and Beyond Long Paper
Session 4B: Jul 6
(18:00-19:00 GMT)

Session 5B: Jul 6
(21:00-22:00 GMT)
Abstract:
Generating multi-sentence descriptions for videos is one of the most challenging captioning tasks due to its high requirements for not only visual relevance but also discourse-based coherence across the sentences in the paragraph. Towards this goal, we propose a new approach called Memory-Augmented Recurrent Transformer (MART), which uses a memory module to augment the transformer architecture. The memory module generates a highly summarized memory state from the video segments and the sentence history so as to help better prediction of the next sentence (w.r.t. coreference and repetition aspects), thus encouraging coherent paragraph generation. Extensive experiments, human evaluations, and qualitative analyses on two popular datasets ActivityNet Captions and YouCookII show that MART generates more coherent and less repetitive paragraph captions than baseline methods, while maintaining relevance to the input video events.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
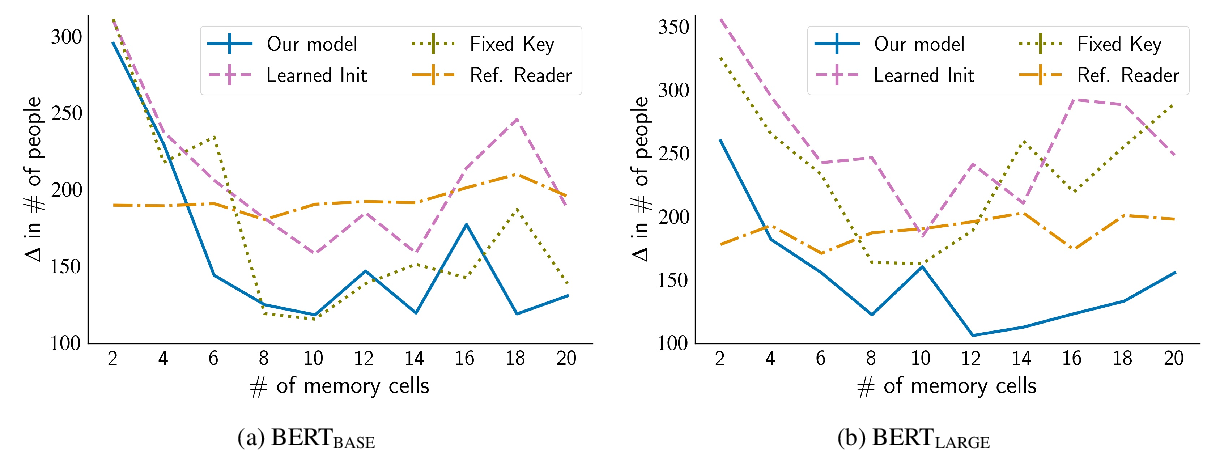
PeTra: A Sparsely Supervised Memory Model for People Tracking
Shubham Toshniwal, Allyson Ettinger, Kevin Gimpel, Karen Livescu,
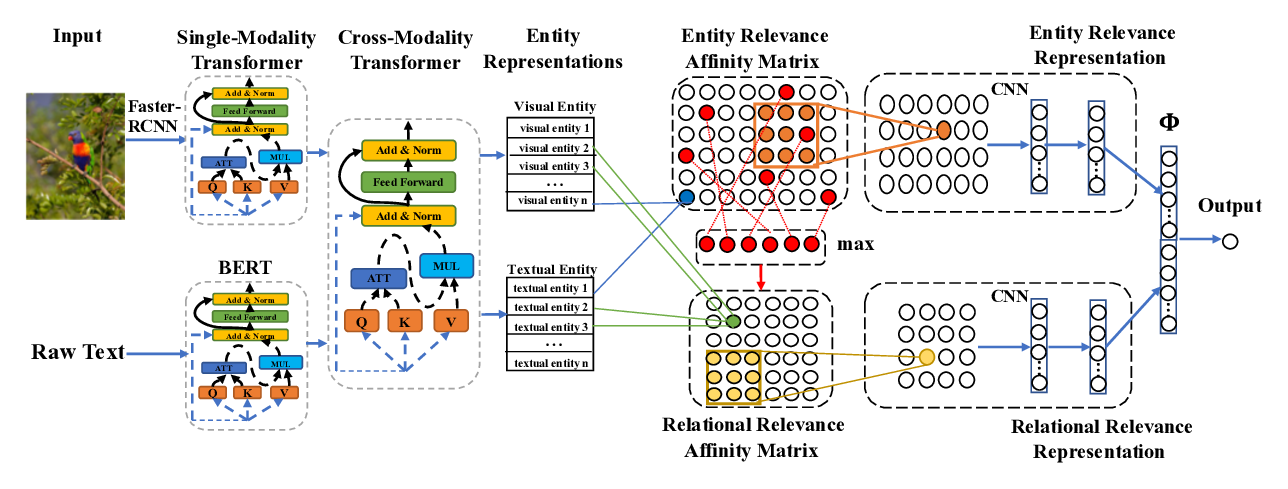
Cross-Modality Relevance for Reasoning on Language and Vision
Chen Zheng, Quan Guo, Parisa Kordjamshidi,
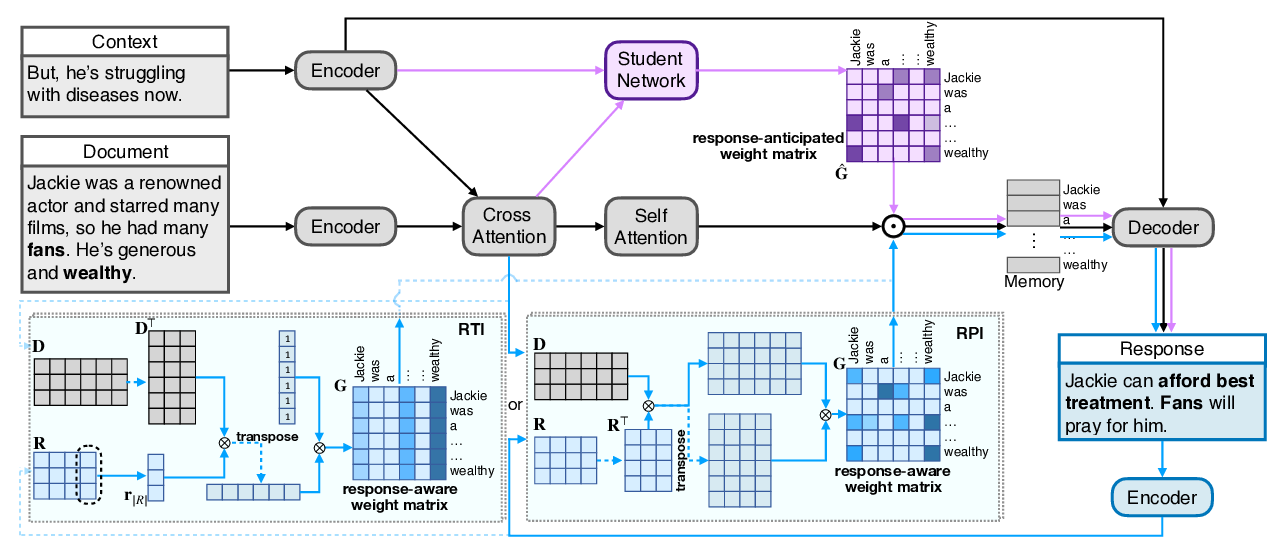
Response-Anticipated Memory for On-Demand Knowledge Integration in Response Generation
Zhiliang Tian, Wei Bi, Dongkyu Lee, Lanqing Xue, Yiping Song, Xiaojiang Liu, Nevin L. Zhang,