Pretrained Transformers Improve Out-of-Distribution Robustness
Dan Hendrycks, Xiaoyuan Liu, Eric Wallace, Adam Dziedzic, Rishabh Krishnan, Dawn Song
Machine Learning for NLP Short Paper
Session 4B: Jul 6
(18:00-19:00 GMT)

Session 5B: Jul 6
(21:00-22:00 GMT)
Abstract:
Although pretrained Transformers such as BERT achieve high accuracy on in-distribution examples, do they generalize to new distributions? We systematically measure out-of-distribution (OOD) generalization for seven NLP datasets by constructing a new robustness benchmark with realistic distribution shifts. We measure the generalization of previous models including bag-of-words models, ConvNets, and LSTMs, and we show that pretrained Transformers' performance declines are substantially smaller. Pretrained transformers are also more effective at detecting anomalous or OOD examples, while many previous models are frequently worse than chance. We examine which factors affect robustness, finding that larger models are not necessarily more robust, distillation can be harmful, and more diverse pretraining data can enhance robustness. Finally, we show where future work can improve OOD robustness.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
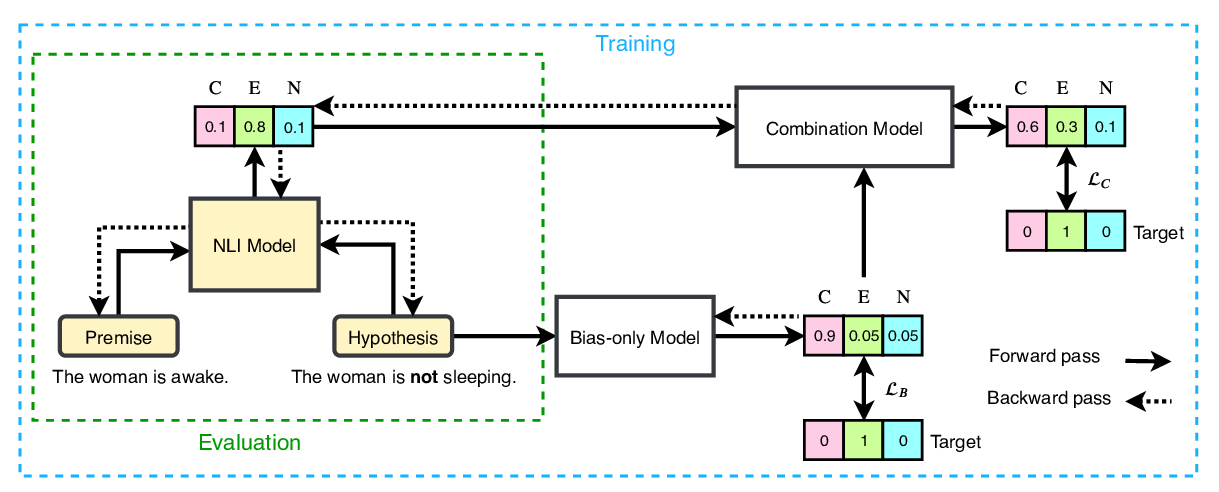
End-to-End Bias Mitigation by Modelling Biases in Corpora
Rabeeh Karimi Mahabadi, Yonatan Belinkov, James Henderson,
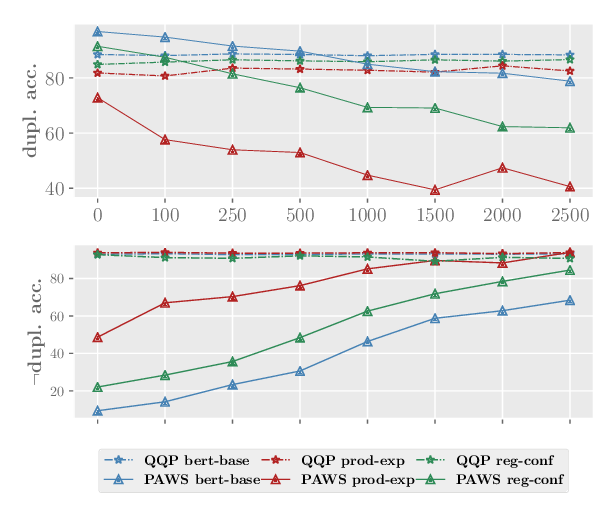
Mind the Trade-off: Debiasing NLU Models without Degrading the In-distribution Performance
Prasetya Ajie Utama, Nafise Sadat Moosavi, Iryna Gurevych,
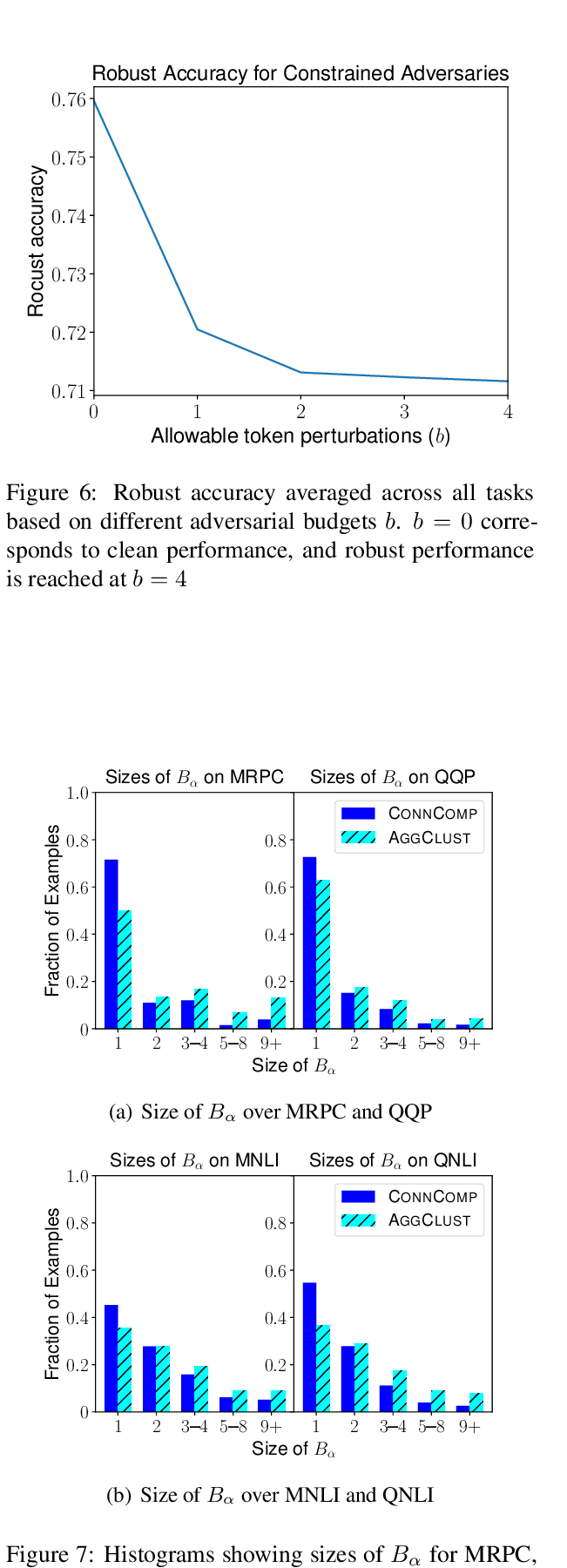
Robust Encodings: A Framework for Combating Adversarial Typos
Erik Jones, Robin Jia, Aditi Raghunathan, Percy Liang,
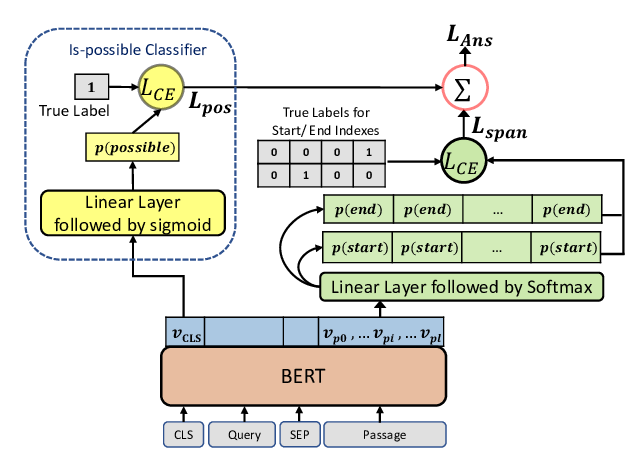
Span Selection Pre-training for Question Answering
Michael Glass, Alfio Gliozzo, Rishav Chakravarti, Anthony Ferritto, Lin Pan, G P Shrivatsa Bhargav, Dinesh Garg, Avi Sil,