Mind the Trade-off: Debiasing NLU Models without Degrading the In-distribution Performance
Prasetya Ajie Utama, Nafise Sadat Moosavi, Iryna Gurevych
Semantics: Textual Inference and Other Areas of Semantics Long Paper
Session 14B: Jul 8
(18:00-19:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
Models for natural language understanding (NLU) tasks often rely on the idiosyncratic biases of the dataset, which make them brittle against test cases outside the training distribution. Recently, several proposed debiasing methods are shown to be very effective in improving out-of-distribution performance. However, their improvements come at the expense of performance drop when models are evaluated on the in-distribution data, which contain examples with higher diversity. This seemingly inevitable trade-off may not tell us much about the changes in the reasoning and understanding capabilities of the resulting models on broader types of examples beyond the small subset represented in the out-of-distribution data. In this paper, we address this trade-off by introducing a novel debiasing method, called confidence regularization, which discourage models from exploiting biases while enabling them to receive enough incentive to learn from all the training examples. We evaluate our method on three NLU tasks and show that, in contrast to its predecessors, it improves the performance on out-of-distribution datasets (e.g., 7pp gain on HANS dataset) while maintaining the original in-distribution accuracy.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
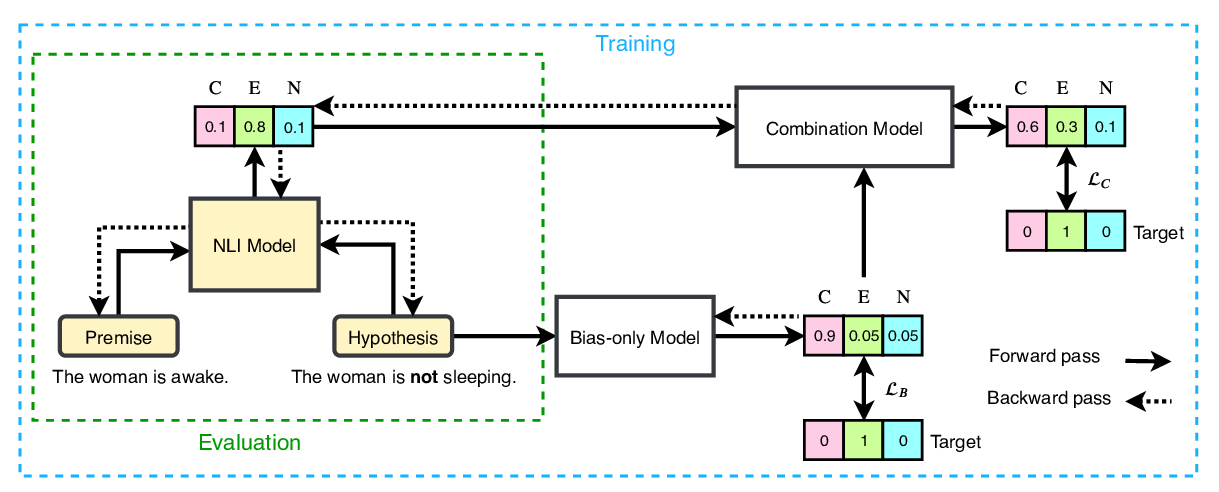
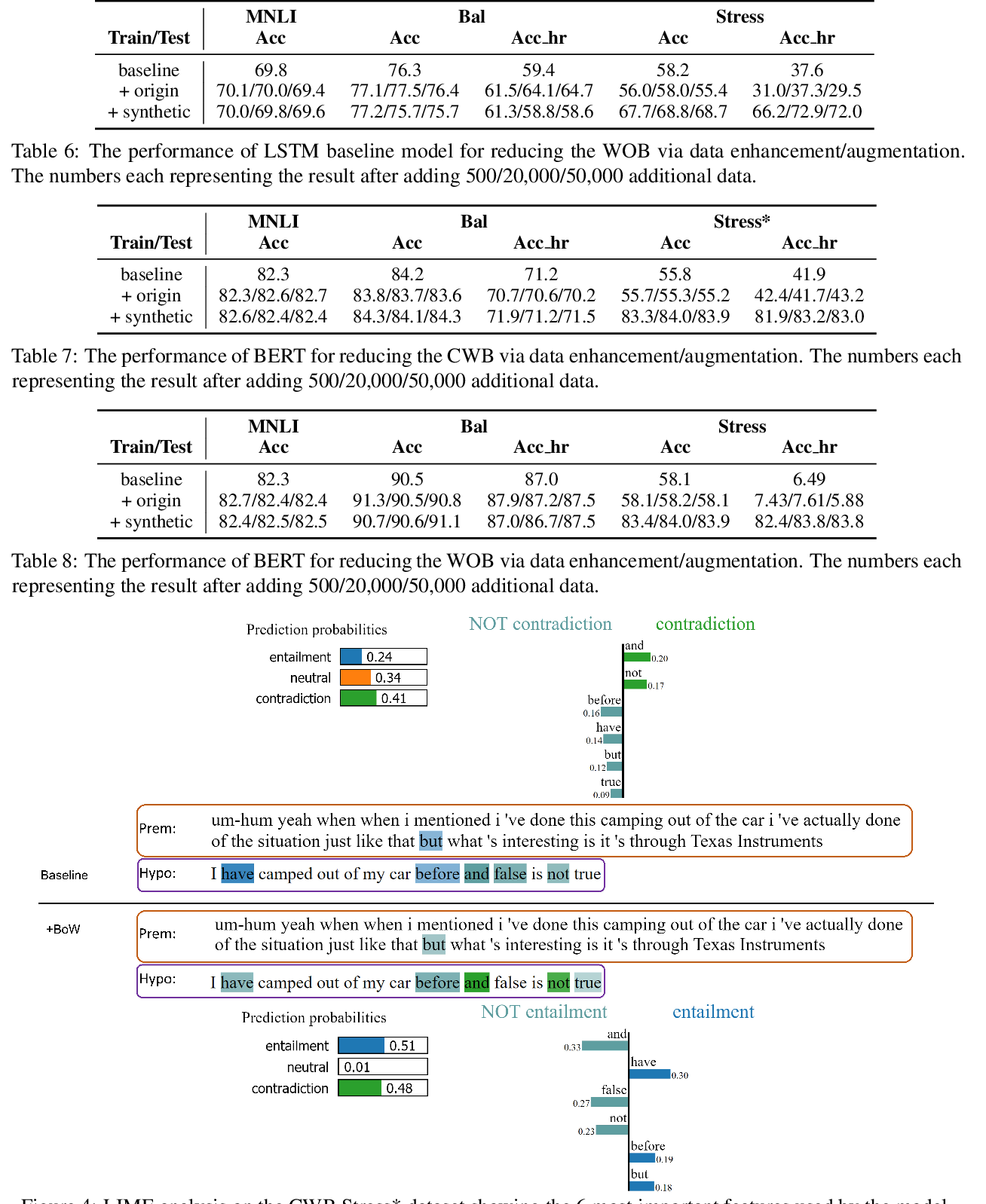
End-to-End Bias Mitigation by Modelling Biases in Corpora
Rabeeh Karimi Mahabadi, Yonatan Belinkov, James Henderson,
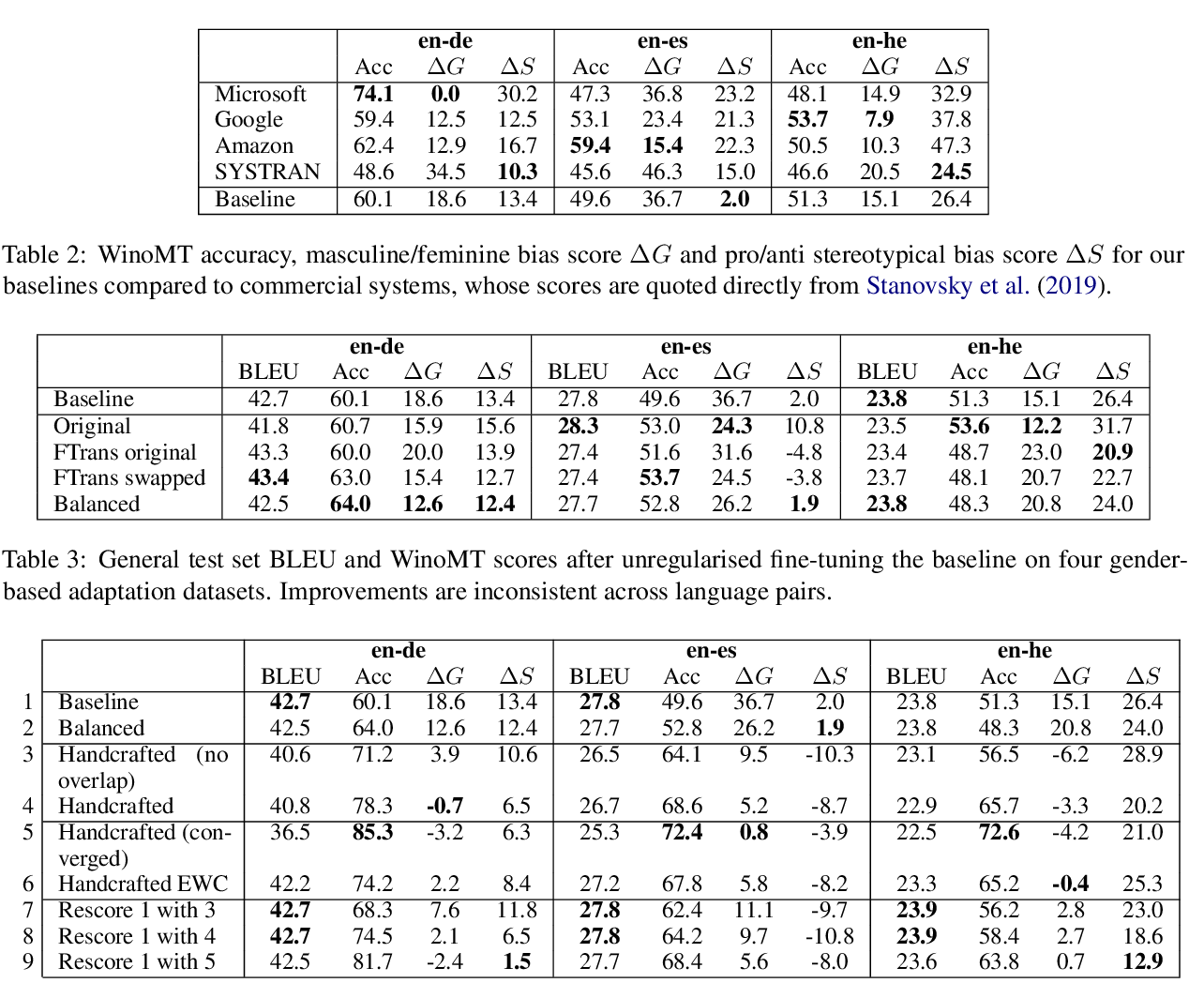
Reducing Gender Bias in Neural Machine Translation as a Domain Adaptation Problem
Danielle Saunders, Bill Byrne,