Weight Poisoning Attacks on Pretrained Models
Keita Kurita, Paul Michel, Graham Neubig
Machine Learning for NLP Long Paper
Session 4B: Jul 6
(18:00-19:00 GMT)

Session 5B: Jul 6
(21:00-22:00 GMT)
Abstract:
Recently, NLP has seen a surge in the usage of large pre-trained models. Users download weights of models pre-trained on large datasets, then fine-tune the weights on a task of their choice. This raises the question of whether downloading untrusted pre-trained weights can pose a security threat. In this paper, we show that it is possible to construct ``weight poisoning'' attacks where pre-trained weights are injected with vulnerabilities that expose ``backdoors'' after fine-tuning, enabling the attacker to manipulate the model prediction simply by injecting an arbitrary keyword. We show that by applying a regularization method which we call RIPPLe and an initialization procedure we call Embedding Surgery, such attacks are possible even with limited knowledge of the dataset and fine-tuning procedure. Our experiments on sentiment classification, toxicity detection, and spam detection show that this attack is widely applicable and poses a serious threat. Finally, we outline practical defenses against such attacks. Code to reproduce our experiments is available at https://github.com/neulab/RIPPLe.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
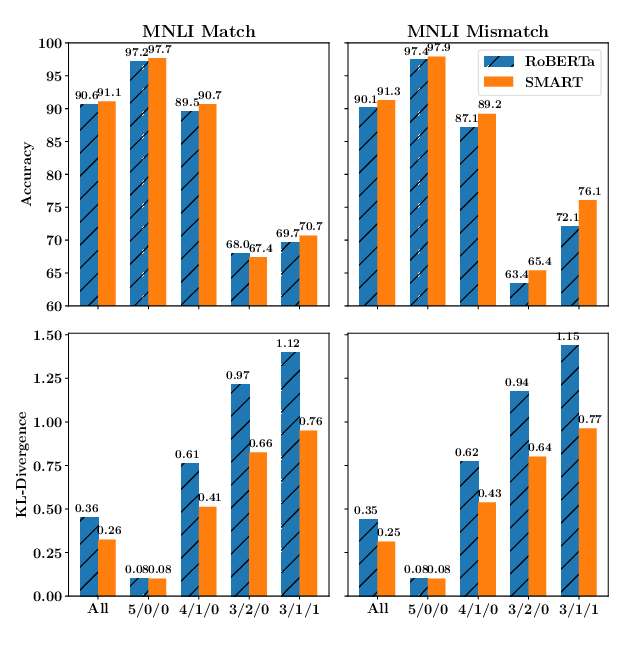
SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization
Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, Tuo Zhao,
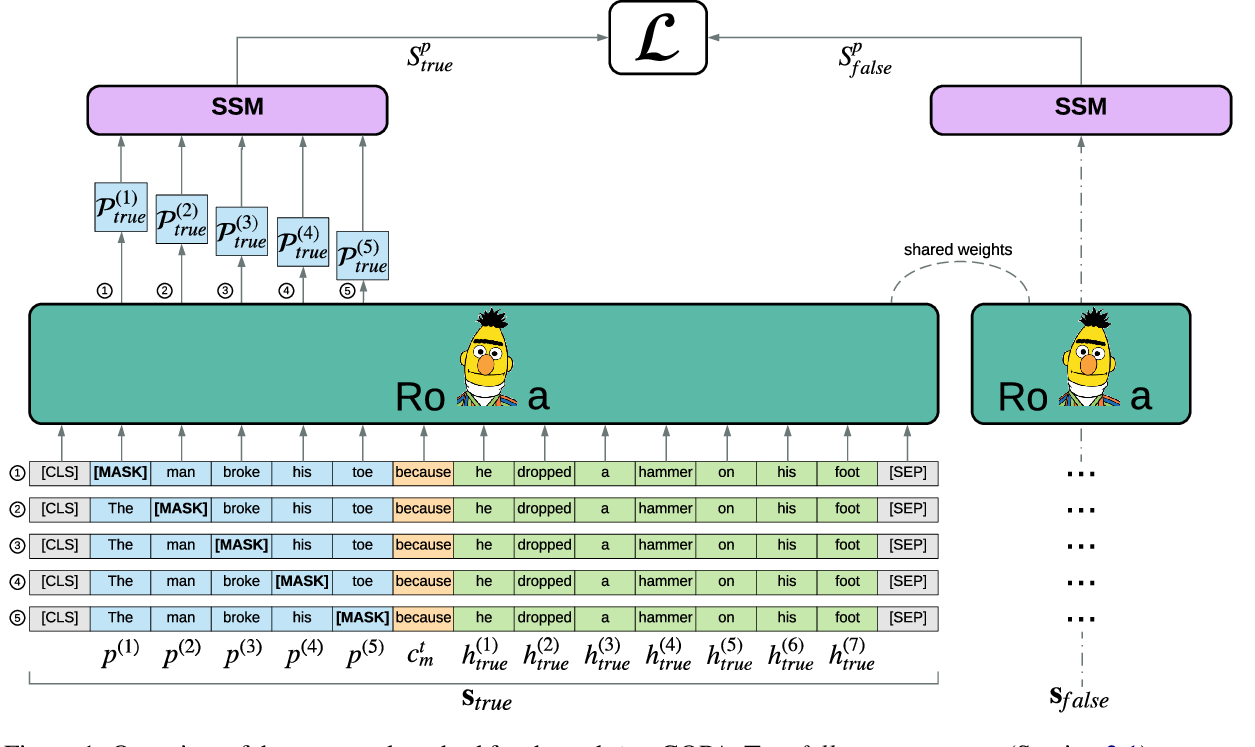
Pre-training Is (Almost) All You Need: An Application to Commonsense Reasoning
Alexandre Tamborrino, Nicola Pellicanò, Baptiste Pannier, Pascal Voitot, Louise Naudin,
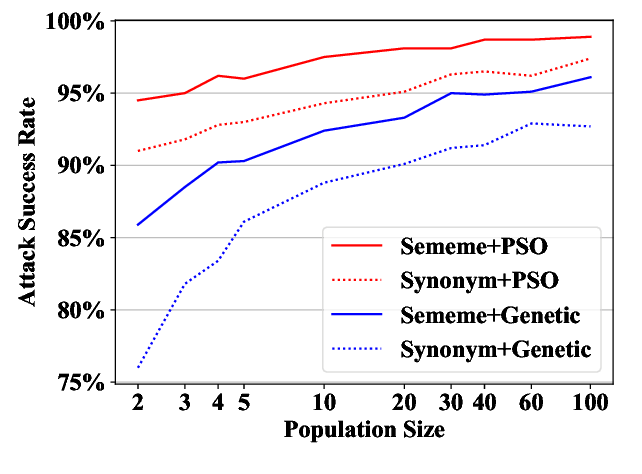
Word-level Textual Adversarial Attacking as Combinatorial Optimization
Yuan Zang, Fanchao Qi, Chenghao Yang, Zhiyuan Liu, Meng Zhang, Qun Liu, Maosong Sun,
Do you have the right scissors? Tailoring Pre-trained Language Models via Monte-Carlo Methods
Ning Miao, Yuxuan Song, Hao Zhou, Lei Li,