Do you have the right scissors? Tailoring Pre-trained Language Models via Monte-Carlo Methods
Ning Miao, Yuxuan Song, Hao Zhou, Lei Li
Machine Learning for NLP Short Paper
Session 6B: Jul 7
(06:00-07:00 GMT)

Session 7B: Jul 7
(09:00-10:00 GMT)
Abstract:
It has been a common approach to pre-train a language model on a large corpus and fine-tune it on task-specific data. In practice, we observe that fine-tuning a pre-trained model on a small dataset may lead to over- and/or under-estimate problem. In this paper, we propose MC-Tailor, a novel method to alleviate the above issue in text generation tasks by truncating and transferring the probability mass from over-estimated regions to under-estimated ones. Experiments on a variety of text generation datasets show that MC-Tailor consistently and significantly outperforms the fine-tuning approach.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization
Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, Tuo Zhao,
Pre-training Is (Almost) All You Need: An Application to Commonsense Reasoning
Alexandre Tamborrino, Nicola Pellicanò, Baptiste Pannier, Pascal Voitot, Louise Naudin,
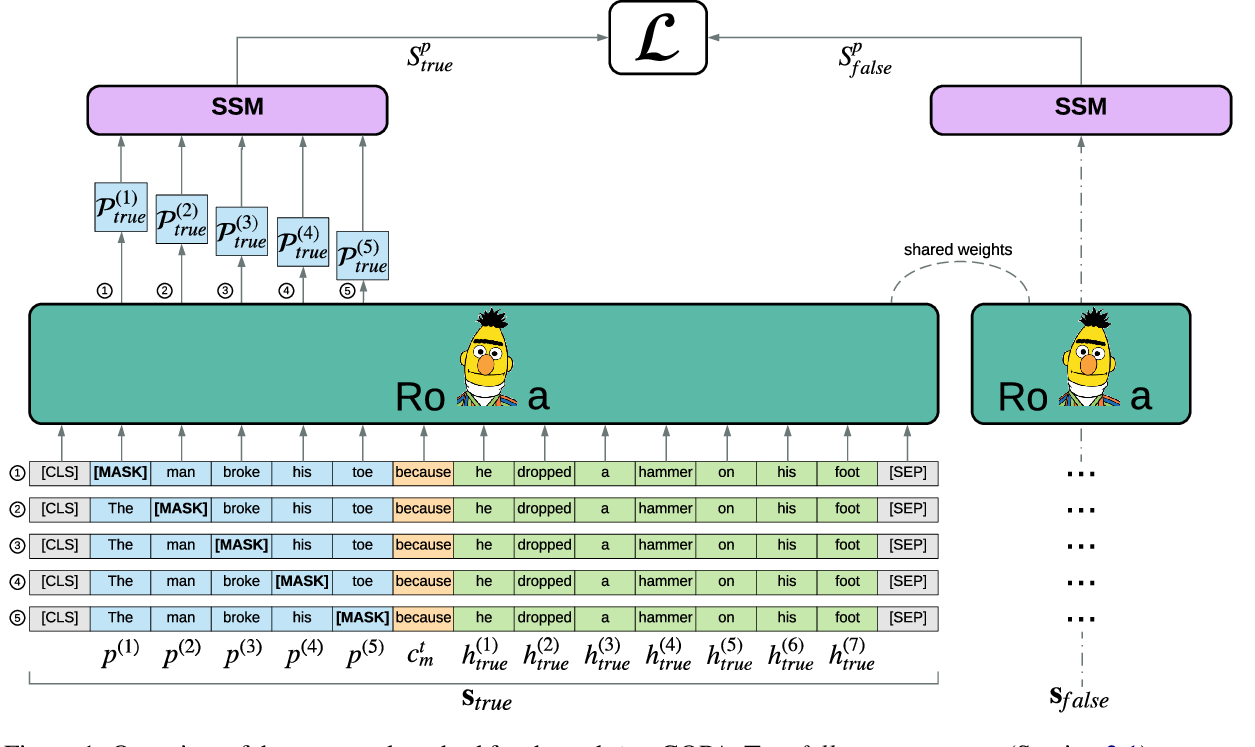
Integrating Multimodal Information in Large Pretrained Transformers
Wasifur Rahman, Md Kamrul Hasan, Sangwu Lee, AmirAli Bagher Zadeh, Chengfeng Mao, Louis-Philippe Morency, Ehsan Hoque,