Understanding Attention for Text Classification
Xiaobing Sun, Wei Lu
Interpretability and Analysis of Models for NLP Long Paper
Session 6B: Jul 7
(06:00-07:00 GMT)

Session 8A: Jul 7
(12:00-13:00 GMT)
Abstract:
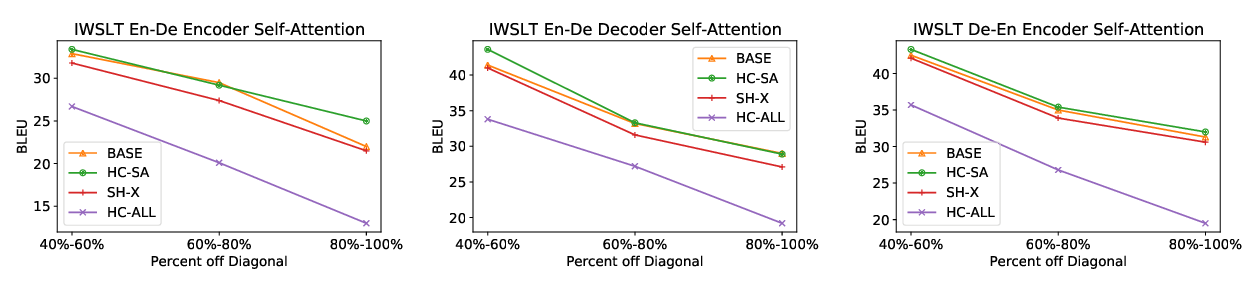
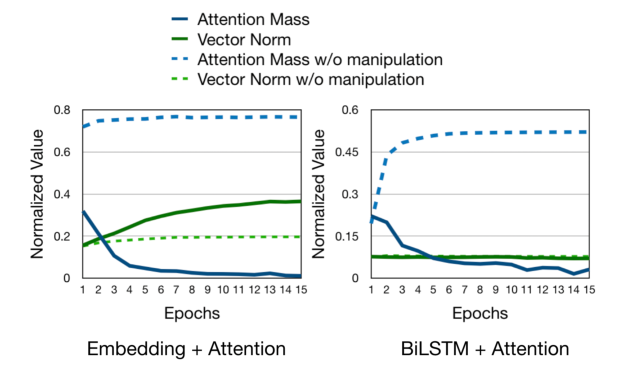
Attention has been proven successful in many natural language processing (NLP) tasks. Recently, many researchers started to investigate the interpretability of attention on NLP tasks. Many existing approaches focused on examining whether the local attention weights could reflect the importance of input representations. In this work, we present a study on understanding the internal mechanism of attention by looking into the gradient update process, checking its behavior when approaching a local minimum during training. We propose to analyze for each word token the following two quantities: its polarity score and its attention score, where the latter is a global assessment on the token’s significance. We discuss conditions under which the attention mechanism may become more (or less) interpretable, and show how the interplay between the two quantities can contribute towards model performance.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Learning to Deceive with Attention-Based Explanations
Danish Pruthi, Mansi Gupta, Bhuwan Dhingra, Graham Neubig, Zachary C. Lipton,
Human Attention Maps for Text Classification: Do Humans and Neural Networks Focus on the Same Words?
Cansu Sen, Thomas Hartvigsen, Biao Yin, Xiangnan Kong, Elke Rundensteiner,