Adaptive Compression of Word Embeddings
Yeachan Kim, Kang-Min Kim, SangKeun Lee
Semantics: Lexical Long Paper
Session 7A: Jul 7
(08:00-09:00 GMT)

Session 8A: Jul 7
(12:00-13:00 GMT)
Abstract:
Distributed representations of words have been an indispensable component for natural language processing (NLP) tasks. However, the large memory footprint of word embeddings makes it challenging to deploy NLP models to memory-constrained devices (e.g., self-driving cars, mobile devices). In this paper, we propose a novel method to adaptively compress word embeddings. We fundamentally follow a code-book approach that represents words as discrete codes such as (8, 5, 2, 4). However, unlike prior works that assign the same length of codes to all words, we adaptively assign different lengths of codes to each word by learning downstream tasks. The proposed method works in two steps. First, each word directly learns to select its code length in an end-to-end manner by applying the Gumbel-softmax tricks. After selecting the code length, each word learns discrete codes through a neural network with a binary constraint. To showcase the general applicability of the proposed method, we evaluate the performance on four different downstream tasks. Comprehensive evaluation results clearly show that our method is effective and makes the highly compressed word embeddings without hurting the task accuracy. Moreover, we show that our model assigns word to each code-book by considering the significance of tasks.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
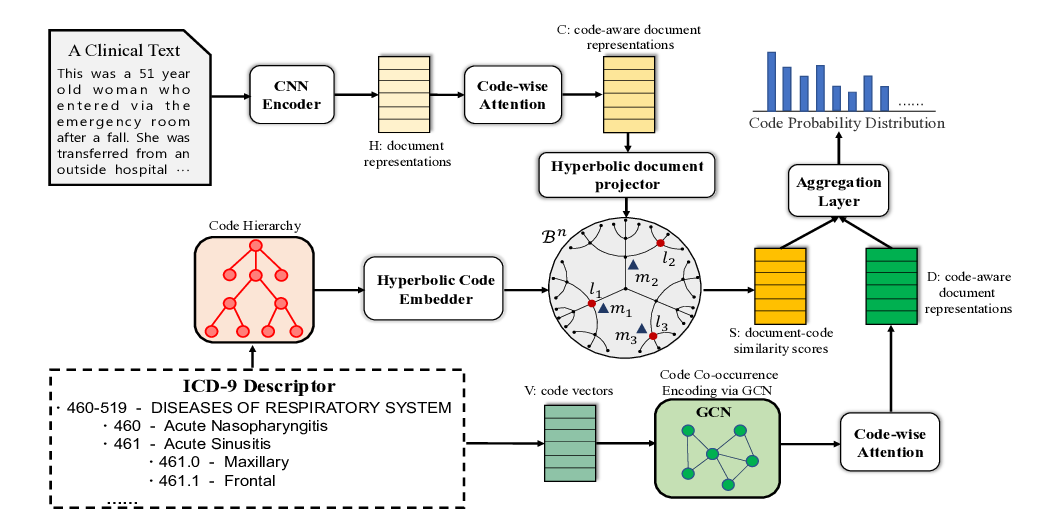
HyperCore: Hyperbolic and Co-graph Representation for Automatic ICD Coding
Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao, Shengping Liu, Weifeng Chong,
A Transformer-based Approach for Source Code Summarization
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang,

Interpreting Pretrained Contextualized Representations via Reductions to Static Embeddings
Rishi Bommasani, Kelly Davis, Claire Cardie,