Interpreting Pretrained Contextualized Representations via Reductions to Static Embeddings
Rishi Bommasani, Kelly Davis, Claire Cardie
Interpretability and Analysis of Models for NLP Long Paper
Session 9A: Jul 7
(17:00-18:00 GMT)

Session 10A: Jul 7
(20:00-21:00 GMT)
Abstract:
Contextualized representations (e.g. ELMo, BERT) have become the default pretrained representations for downstream NLP applications. In some settings, this transition has rendered their static embedding predecessors (e.g. Word2Vec, GloVe) obsolete. As a side-effect, we observe that older interpretability methods for static embeddings --- while more diverse and mature than those available for their dynamic counterparts --- are underutilized in studying newer contextualized representations. Consequently, we introduce simple and fully general methods for converting from contextualized representations to static lookup-table embeddings which we apply to 5 popular pretrained models and 9 sets of pretrained weights. Our analysis of the resulting static embeddings notably reveals that pooling over many contexts significantly improves representational quality under intrinsic evaluation. Complementary to analyzing representational quality, we consider social biases encoded in pretrained representations with respect to gender, race/ethnicity, and religion and find that bias is encoded disparately across pretrained models and internal layers even for models with the same training data. Concerningly, we find dramatic inconsistencies between social bias estimators for word embeddings.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
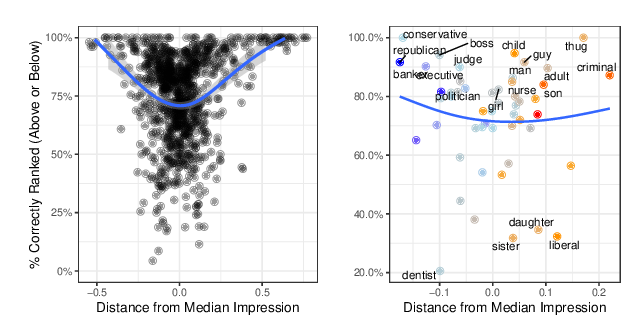
When do Word Embeddings Accurately Reflect Surveys on our Beliefs About People?
Kenneth Joseph, Jonathan Morgan,
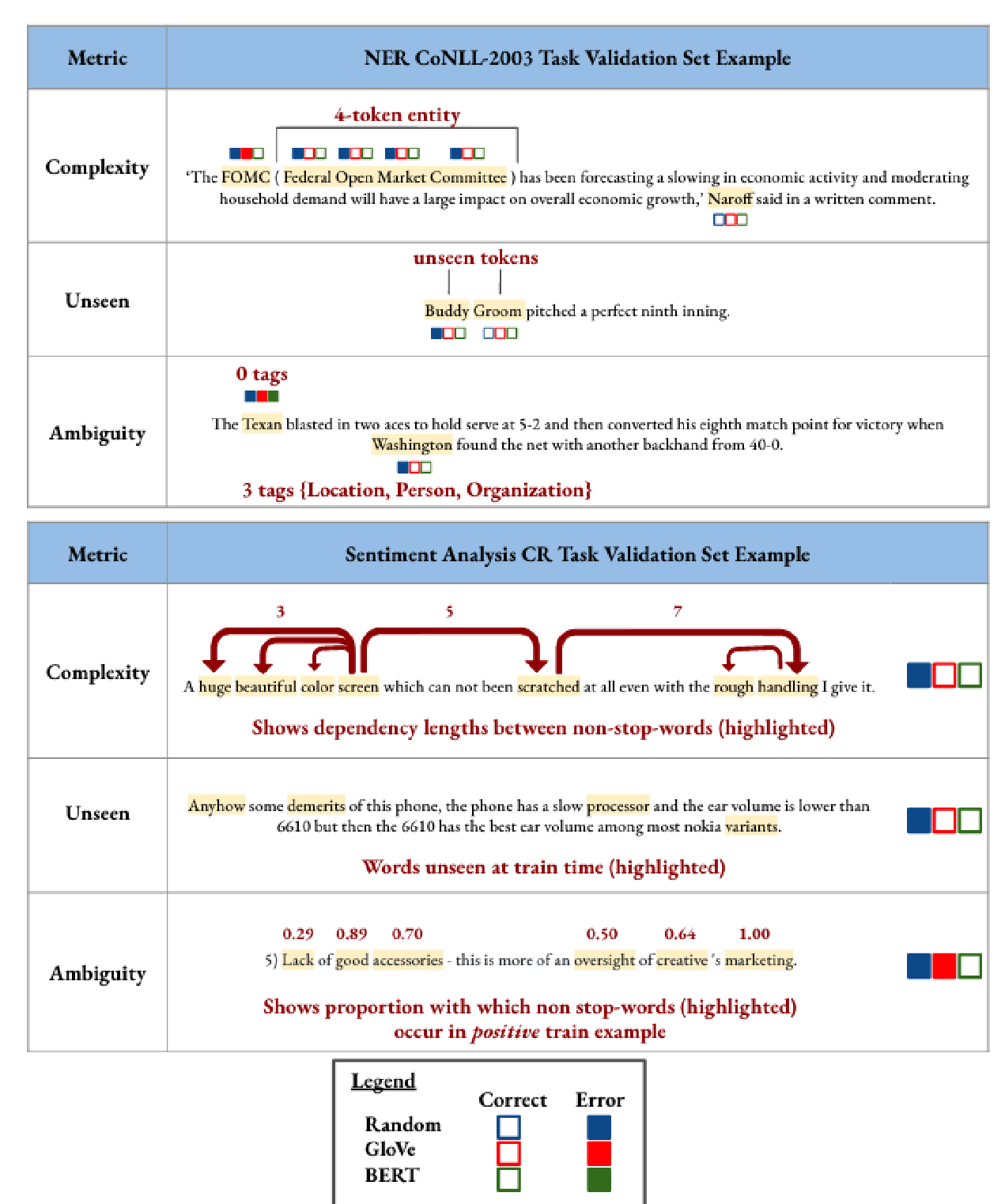
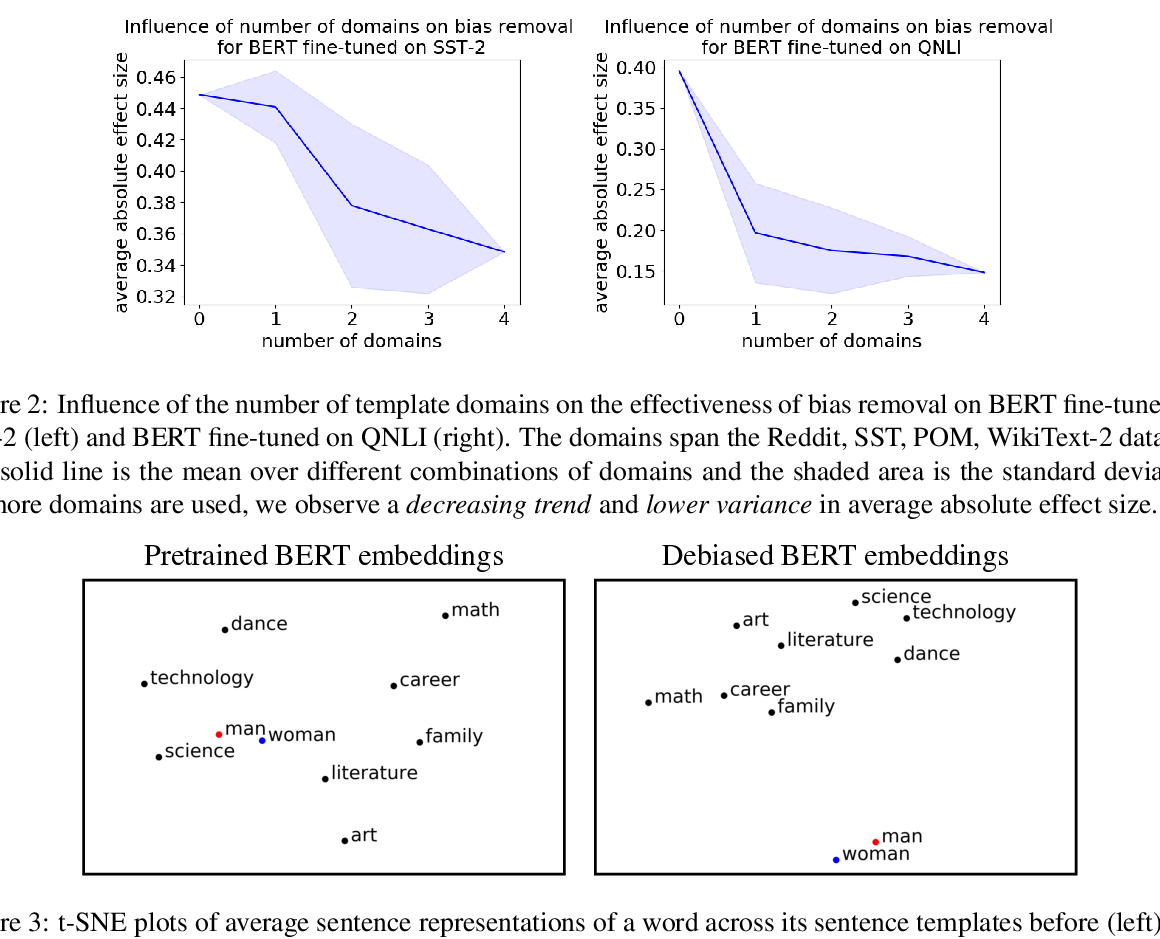
Towards Debiasing Sentence Representations
Paul Pu Liang, Irene Mengze Li, Emily Zheng, Yao Chong Lim, Ruslan Salakhutdinov, Louis-Philippe Morency,
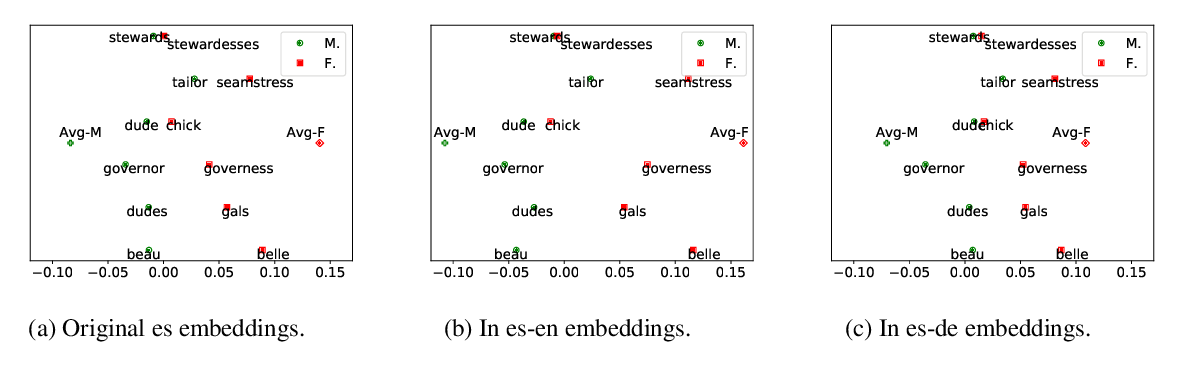
Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer
Jieyu Zhao, Subhabrata Mukherjee, Saghar Hosseini, Kai-Wei Chang, Ahmed Hassan Awadallah,