DeFormer: Decomposing Pre-trained Transformers for Faster Question Answering
Qingqing Cao, Harsh Trivedi, Aruna Balasubramanian, Niranjan Balasubramanian
Question Answering Long Paper
Session 8A: Jul 7
(12:00-13:00 GMT)

Session 10A: Jul 7
(20:00-21:00 GMT)
Abstract:
Transformer-based QA models use input-wide self-attention -- i.e. across both the question and the input passage -- at all layers, causing them to be slow and memory-intensive. It turns out that we can get by without input-wide self-attention at all layers, especially in the lower layers. We introduce DeFormer, a decomposed transformer, which substitutes the full self-attention with question-wide and passage-wide self-attentions in the lower layers. This allows for question-independent processing of the input text representations, which in turn enables pre-computing passage representations reducing runtime compute drastically. Furthermore, because DeFormer is largely similar to the original model, we can initialize DeFormer with the pre-training weights of a standard transformer, and directly fine-tune on the target QA dataset. We show DeFormer versions of BERT and XLNet can be used to speed up QA by over 4.3x and with simple distillation-based losses they incur only a 1% drop in accuracy. We open source the code at https://github.com/StonyBrookNLP/deformer.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
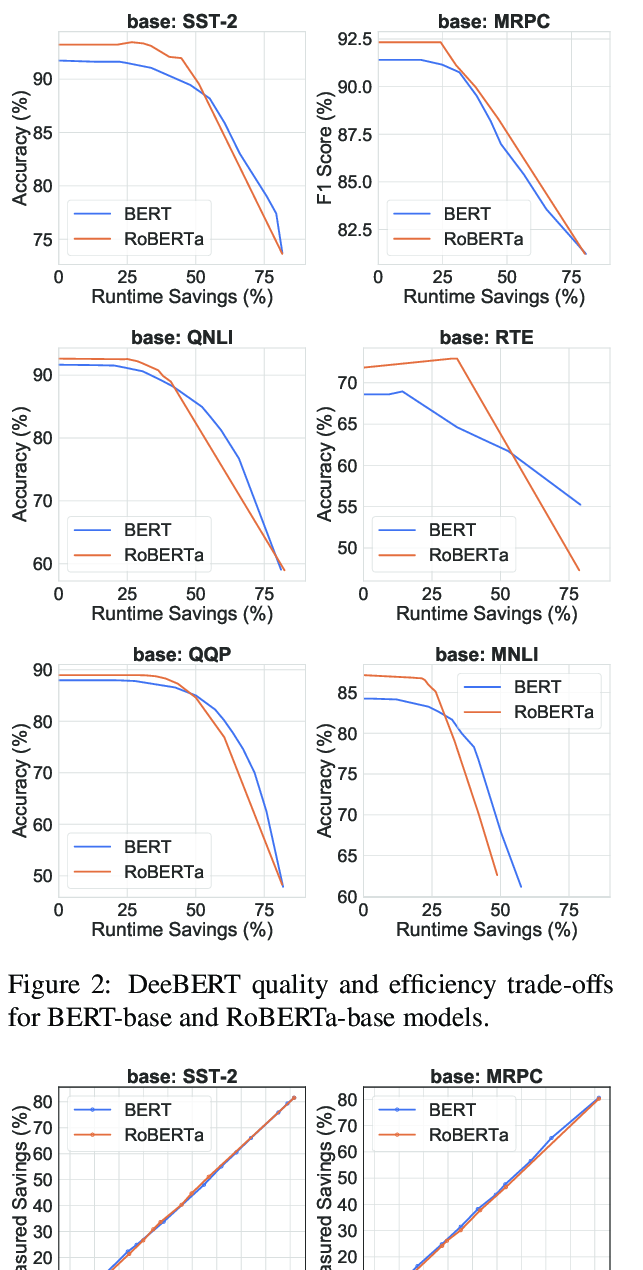
DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference
Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, Jimmy Lin,