Don’t Say That! Making Inconsistent Dialogue Unlikely with Unlikelihood Training
Margaret Li, Stephen Roller, Ilia Kulikov, Sean Welleck, Y-Lan Boureau, Kyunghyun Cho, Jason Weston
Dialogue and Interactive Systems Long Paper
Session 9A: Jul 7
(17:00-18:00 GMT)

Session 10A: Jul 7
(20:00-21:00 GMT)
Abstract:
Generative dialogue models currently suffer from a number of problems which standard maximum likelihood training does not address. They tend to produce generations that (i) rely too much on copying from the context, (ii) contain repetitions within utterances, (iii) overuse frequent words, and (iv) at a deeper level, contain logical flaws.In this work we show how all of these problems can be addressed by extending the recently introduced unlikelihood loss (Welleck et al., 2019) to these cases. We show that appropriate loss functions which regularize generated outputs to match human distributions are effective for the first three issues. For the last important general issue, we show applying unlikelihood to collected data of what a model should not do is effective for improving logical consistency, potentially paving the way to generative models with greater reasoning ability. We demonstrate the efficacy of our approach across several dialogue tasks.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
On Faithfulness and Factuality in Abstractive Summarization
Joshua Maynez, Shashi Narayan, Bernd Bohnet, Ryan McDonald,

Logic-Guided Data Augmentation and Regularization for Consistent Question Answering
Akari Asai, Hannaneh Hajishirzi,
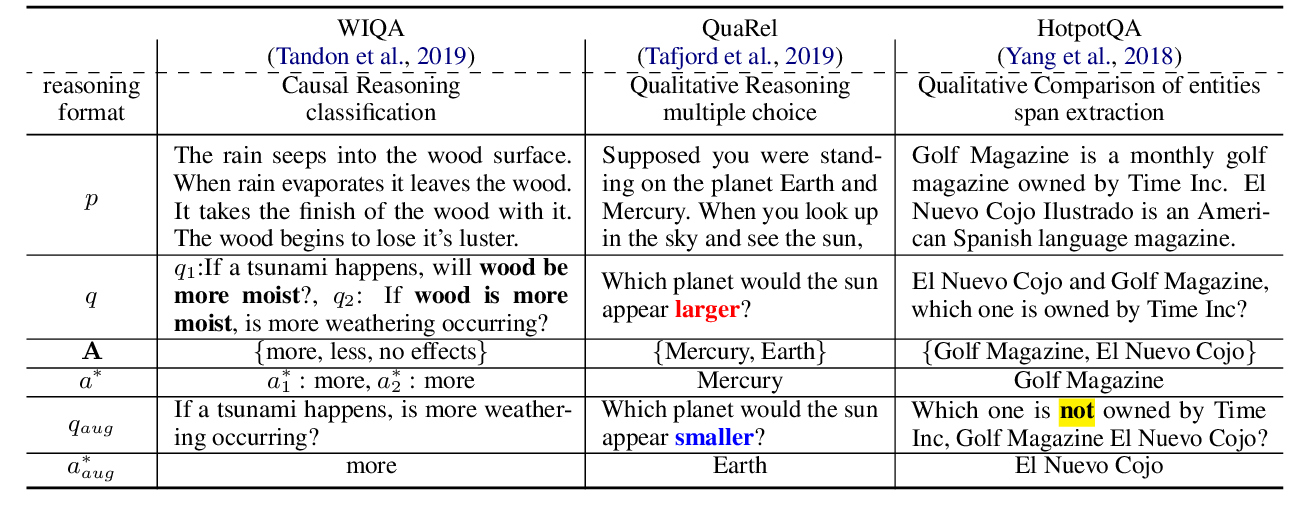
Are Natural Language Inference Models IMPPRESsive? Learning IMPlicature and PRESupposition
Paloma Jeretic, Alex Warstadt, Suvrat Bhooshan, Adina Williams,