How Can We Accelerate Progress Towards Human-like Linguistic Generalization?
Tal Linzen
Theme Short Paper
Session 9A: Jul 7
(17:00-18:00 GMT)

Session 10A: Jul 7
(20:00-21:00 GMT)
Abstract:
This position paper describes and critiques the Pretraining-Agnostic Identically Distributed (PAID) evaluation paradigm, which has become a central tool for measuring progress in natural language understanding. This paradigm consists of three stages: (1) pre-training of a word prediction model on a corpus of arbitrary size; (2) fine-tuning (transfer learning) on a training set representing a classification task; (3) evaluation on a test set drawn from the same distribution as that training set. This paradigm favors simple, low-bias architectures, which, first, can be scaled to process vast amounts of data, and second, can capture the fine-grained statistical properties of a particular data set, regardless of whether those properties are likely to generalize to examples of the task outside the data set. This contrasts with humans, who learn language from several orders of magnitude less data than the systems favored by this evaluation paradigm, and generalize to new tasks in a consistent way. We advocate for supplementing or replacing PAID with paradigms that reward architectures that generalize as quickly and robustly as humans.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
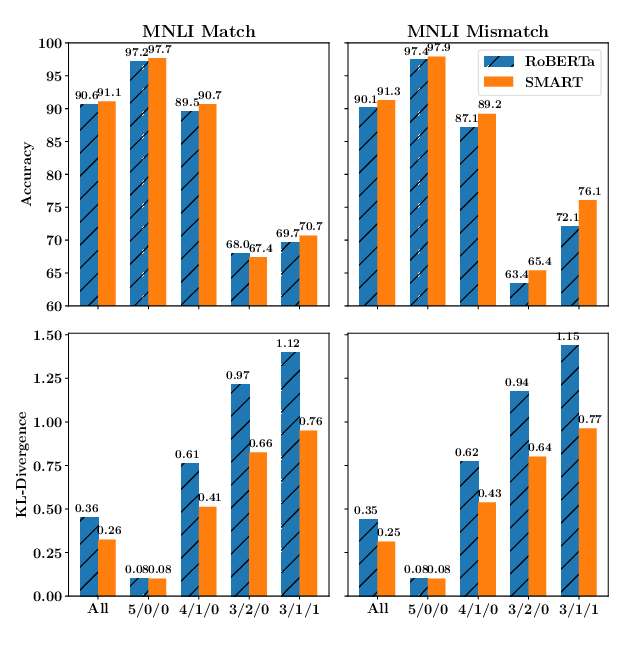
SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization
Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, Tuo Zhao,
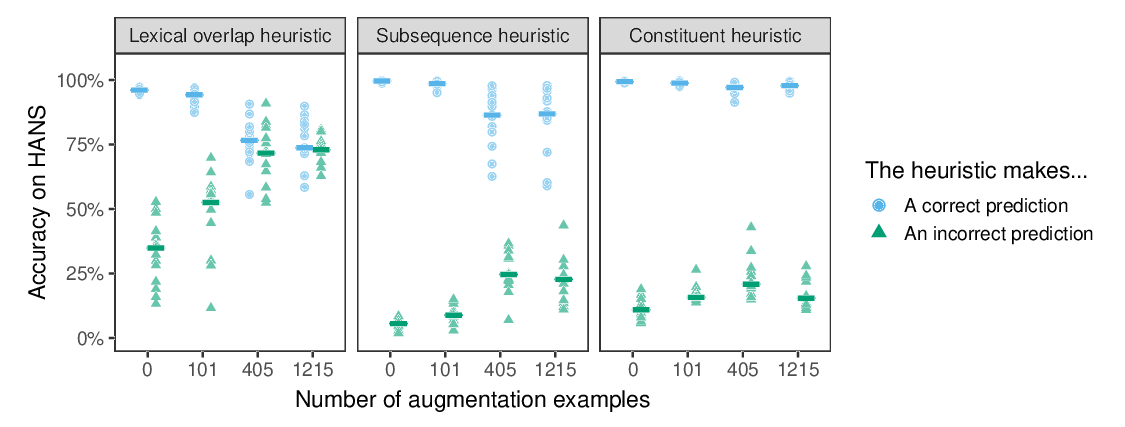
Syntactic Data Augmentation Increases Robustness to Inference Heuristics
Junghyun Min, R. Thomas McCoy, Dipanjan Das, Emily Pitler, Tal Linzen,
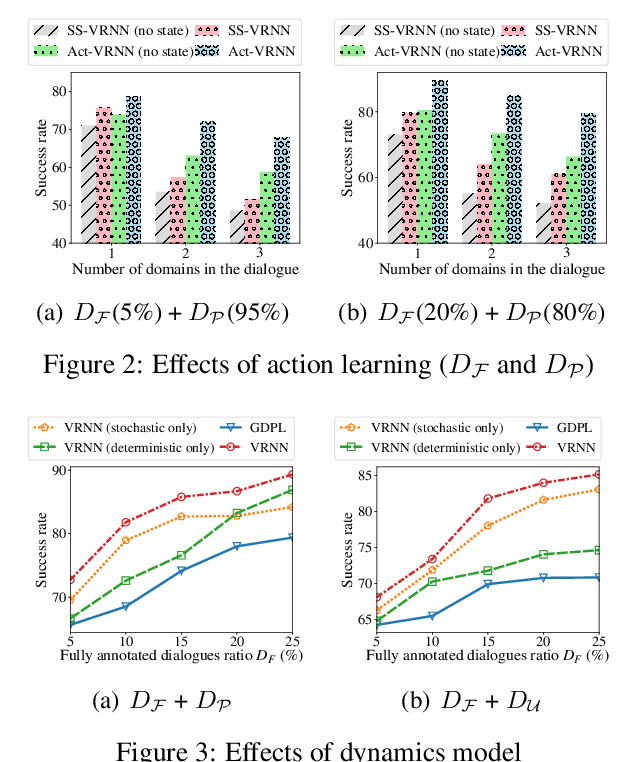
Semi-Supervised Dialogue Policy Learning via Stochastic Reward Estimation
Xinting Huang, Jianzhong Qi, Yu Sun, Rui Zhang,