Evaluating Explainable AI: Which Algorithmic Explanations Help Users Predict Model Behavior?
Peter Hase, Mohit Bansal
Interpretability and Analysis of Models for NLP Long Paper
Session 9B: Jul 7
(18:00-19:00 GMT)

Session 10A: Jul 7
(20:00-21:00 GMT)
Abstract:
Algorithmic approaches to interpreting machine learning models have proliferated in recent years. We carry out human subject tests that are the first of their kind to isolate the effect of algorithmic explanations on a key aspect of model interpretability, simulatability, while avoiding important confounding experimental factors. A model is simulatable when a person can predict its behavior on new inputs. Through two kinds of simulation tests involving text and tabular data, we evaluate five explanations methods: (1) LIME, (2) Anchor, (3) Decision Boundary, (4) a Prototype model, and (5) a Composite approach that combines explanations from each method. Clear evidence of method effectiveness is found in very few cases: LIME improves simulatability in tabular classification, and our Prototype method is effective in counterfactual simulation tests. We also collect subjective ratings of explanations, but we do not find that ratings are predictive of how helpful explanations are. Our results provide the first reliable and comprehensive estimates of how explanations influence simulatability across a variety of explanation methods and data domains. We show that (1) we need to be careful about the metrics we use to evaluate explanation methods, and (2) there is significant room for improvement in current methods.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
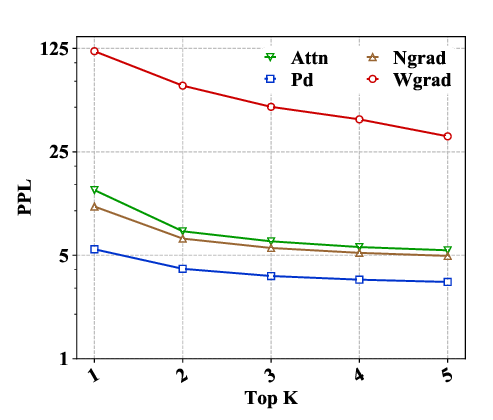
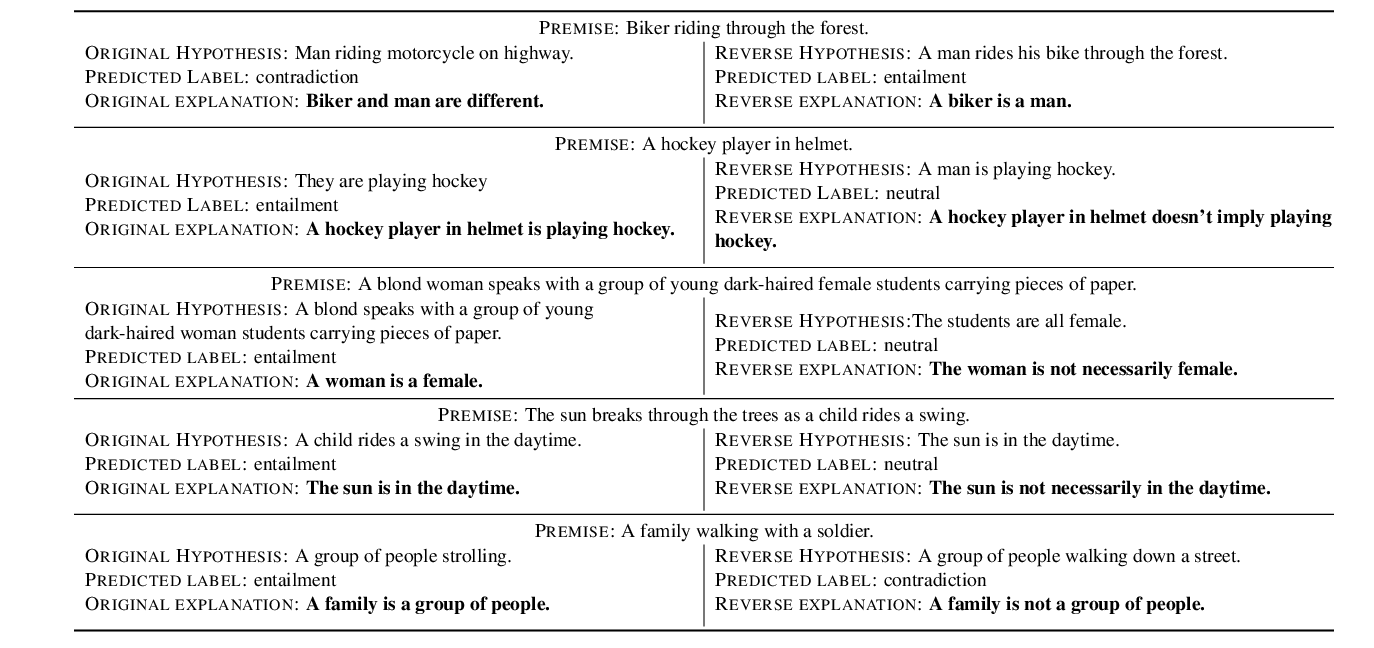
NILE : Natural Language Inference with Faithful Natural Language Explanations
Sawan Kumar, Partha Talukdar,
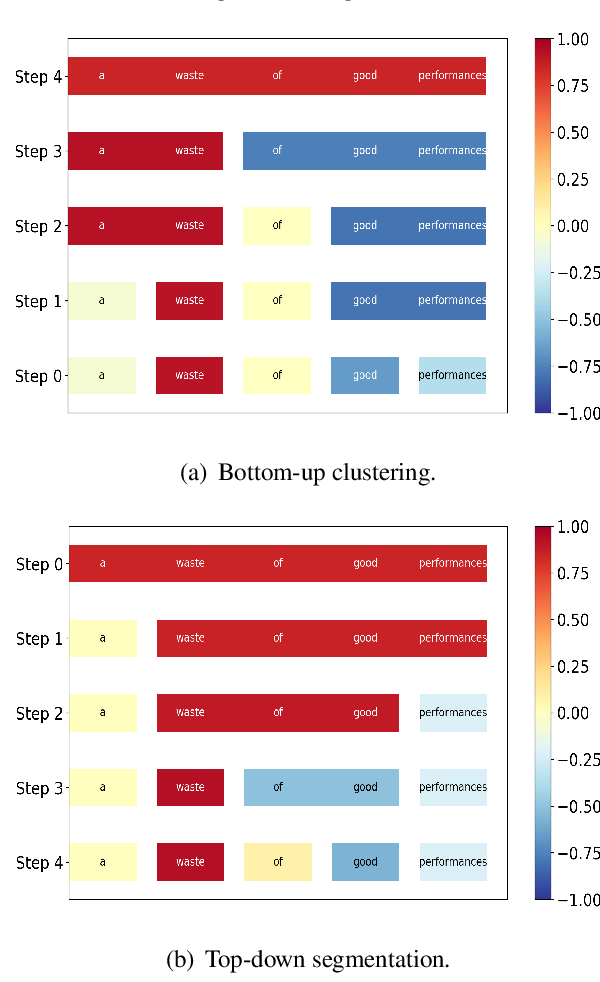
Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection
Hanjie Chen, Guangtao Zheng, Yangfeng Ji,
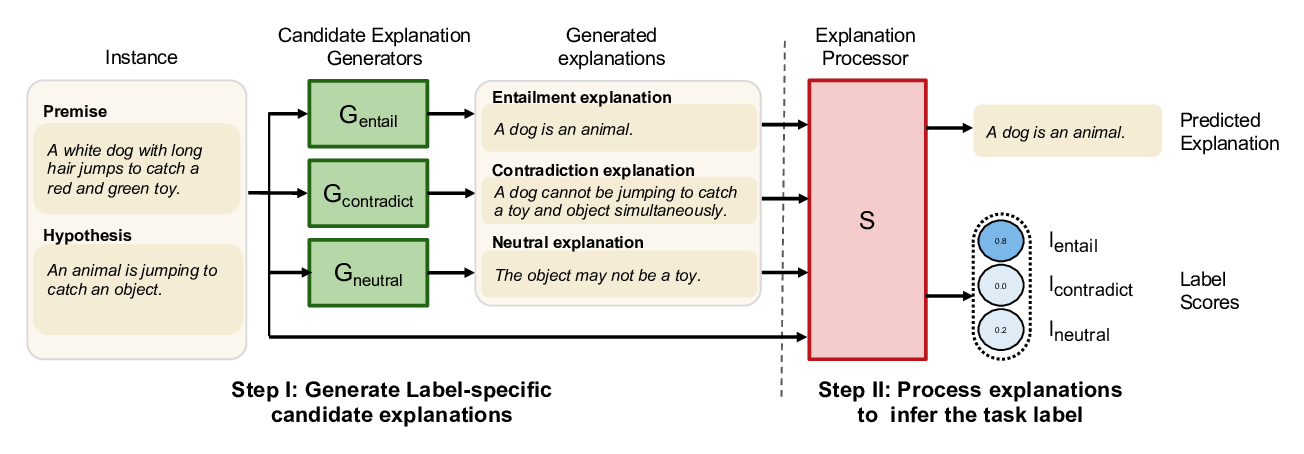
Make Up Your Mind! Adversarial Generation of Inconsistent Natural Language Explanations
Oana-Maria Camburu, Brendan Shillingford, Pasquale Minervini, Thomas Lukasiewicz, Phil Blunsom,
Evaluating Explanation Methods for Neural Machine Translation
Jierui Li, Lemao Liu, Huayang Li, Guanlin Li, Guoping Huang, Shuming Shi,