NILE : Natural Language Inference with Faithful Natural Language Explanations
Sawan Kumar, Partha Talukdar
Semantics: Textual Inference and Other Areas of Semantics Long Paper
Session 14B: Jul 8
(18:00-19:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
The recent growth in the popularity and success of deep learning models on NLP classification tasks has accompanied the need for generating some form of natural language explanation of the predicted labels. Such generated natural language (NL) explanations are expected to be faithful, i.e., they should correlate well with the model's internal decision making. In this work, we focus on the task of natural language inference (NLI) and address the following question: can we build NLI systems which produce labels with high accuracy, while also generating faithful explanations of its decisions? We propose Natural-language Inference over Label-specific Explanations (NILE), a novel NLI method which utilizes auto-generated label-specific NL explanations to produce labels along with its faithful explanation. We demonstrate NILE's effectiveness over previously reported methods through automated and human evaluation of the produced labels and explanations. Our evaluation of NILE also supports the claim that accurate systems capable of providing testable explanations of their decisions can be designed. We discuss the faithfulness of NILE's explanations in terms of sensitivity of the decisions to the corresponding explanations. We argue that explicit evaluation of faithfulness, in addition to label and explanation accuracy, is an important step in evaluating model's explanations. Further, we demonstrate that task-specific probes are necessary to establish such sensitivity.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
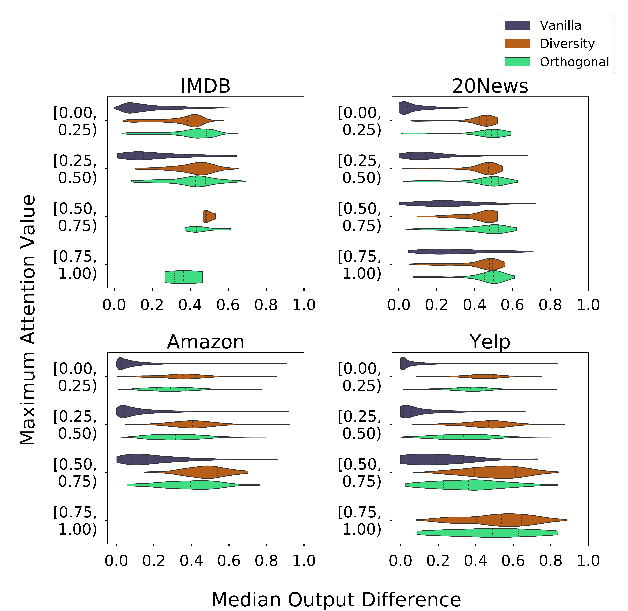
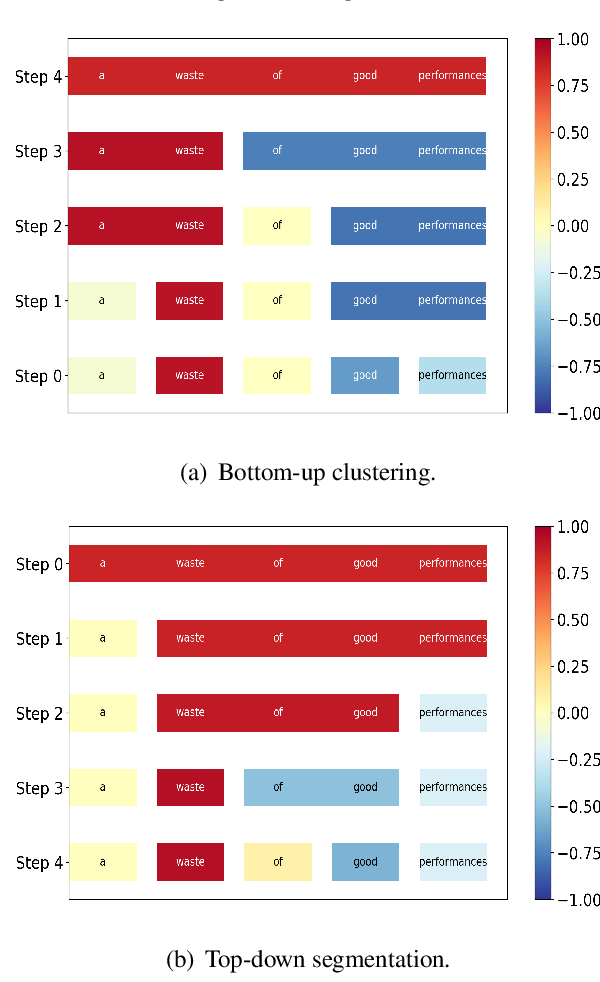
Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection
Hanjie Chen, Guangtao Zheng, Yangfeng Ji,
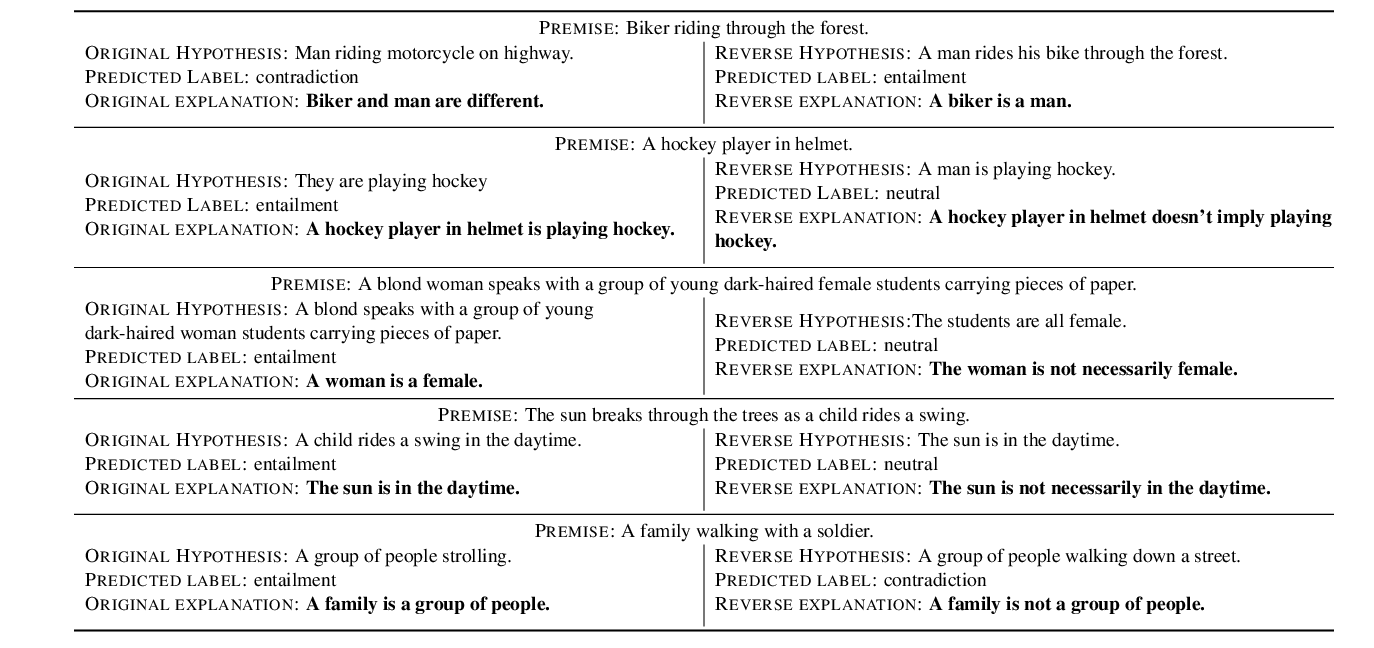
Make Up Your Mind! Adversarial Generation of Inconsistent Natural Language Explanations
Oana-Maria Camburu, Brendan Shillingford, Pasquale Minervini, Thomas Lukasiewicz, Phil Blunsom,
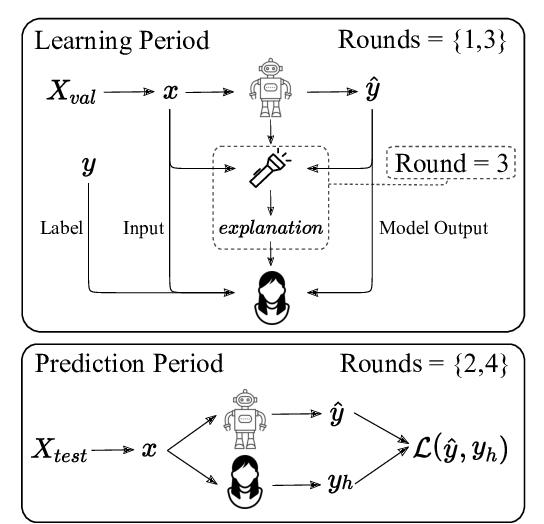
Evaluating Explainable AI: Which Algorithmic Explanations Help Users Predict Model Behavior?
Peter Hase, Mohit Bansal,
Towards Transparent and Explainable Attention Models
Akash Kumar Mohankumar, Preksha Nema, Sharan Narasimhan, Mitesh M. Khapra, Balaji Vasan Srinivasan, Balaraman Ravindran,