Selective Question Answering under Domain Shift
Amita Kamath, Robin Jia, Percy Liang
Question Answering Long Paper
Session 9B: Jul 7
(18:00-19:00 GMT)

Session 10A: Jul 7
(20:00-21:00 GMT)
Abstract:
To avoid giving wrong answers, question answering (QA) models need to know when to abstain from answering. Moreover, users often ask questions that diverge from the model's training data, making errors more likely and thus abstention more critical. In this work, we propose the setting of selective question answering under domain shift, in which a QA model is tested on a mixture of in-domain and out-of-domain data, and must answer (i.e., not abstain on) as many questions as possible while maintaining high accuracy. Abstention policies based solely on the model's softmax probabilities fare poorly, since models are overconfident on out-of-domain inputs. Instead, we train a calibrator to identify inputs on which the QA model errs, and abstain when it predicts an error is likely. Crucially, the calibrator benefits from observing the model's behavior on out-of-domain data, even if from a different domain than the test data. We combine this method with a SQuAD-trained QA model and evaluate on mixtures of SQuAD and five other QA datasets. Our method answers 56% of questions while maintaining 80% accuracy; in contrast, directly using the model's probabilities only answers 48% at 80% accuracy.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
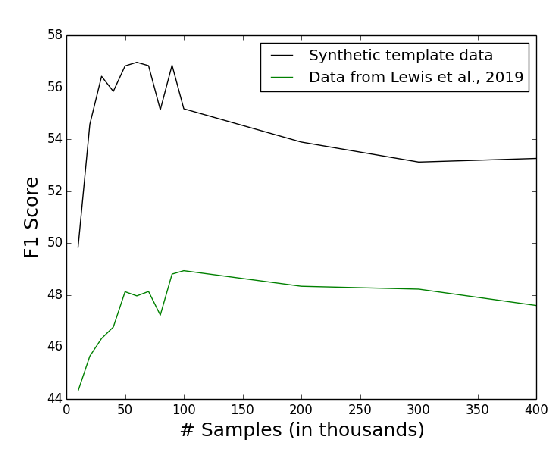
Template-Based Question Generation from Retrieved Sentences for Improved Unsupervised Question Answering
Alexander Fabbri, Patrick Ng, Zhiguo Wang, Ramesh Nallapati, Bing Xiang,
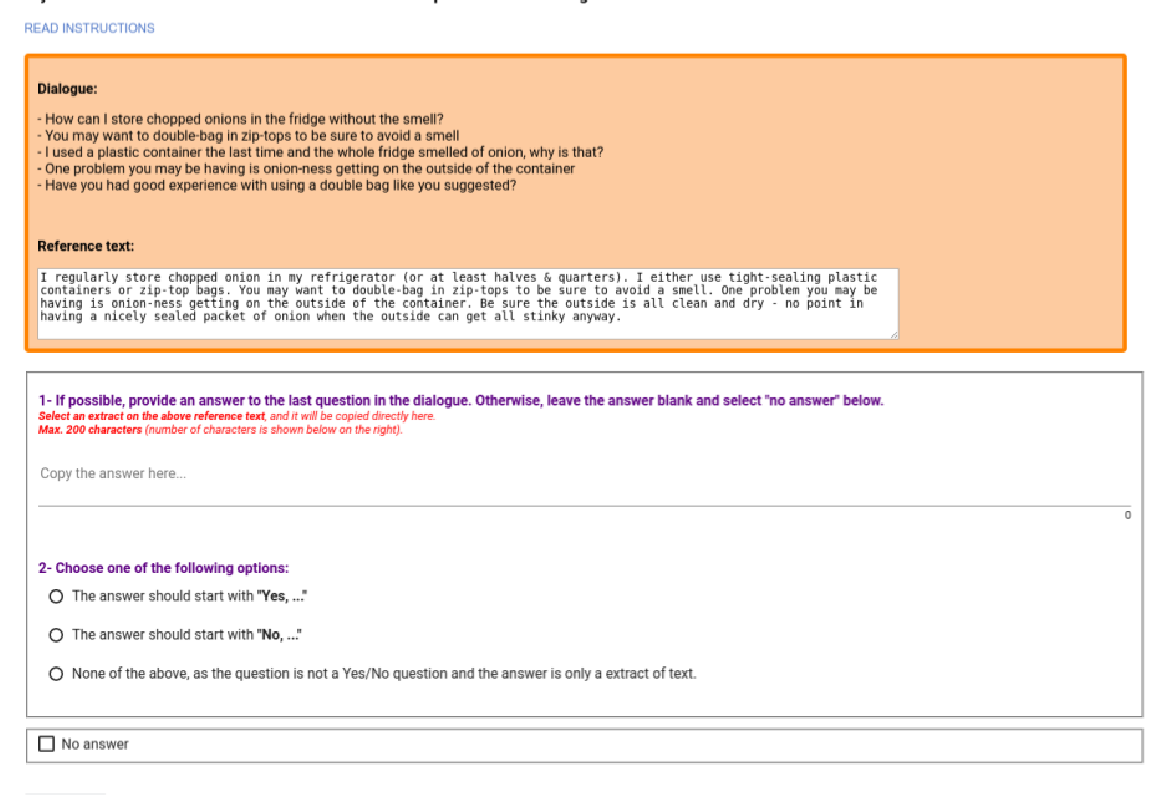
DoQA - Accessing Domain-Specific FAQs via Conversational QA
Jon Ander Campos, Arantxa Otegi, Aitor Soroa, Jan Deriu, Mark Cieliebak, Eneko Agirre,
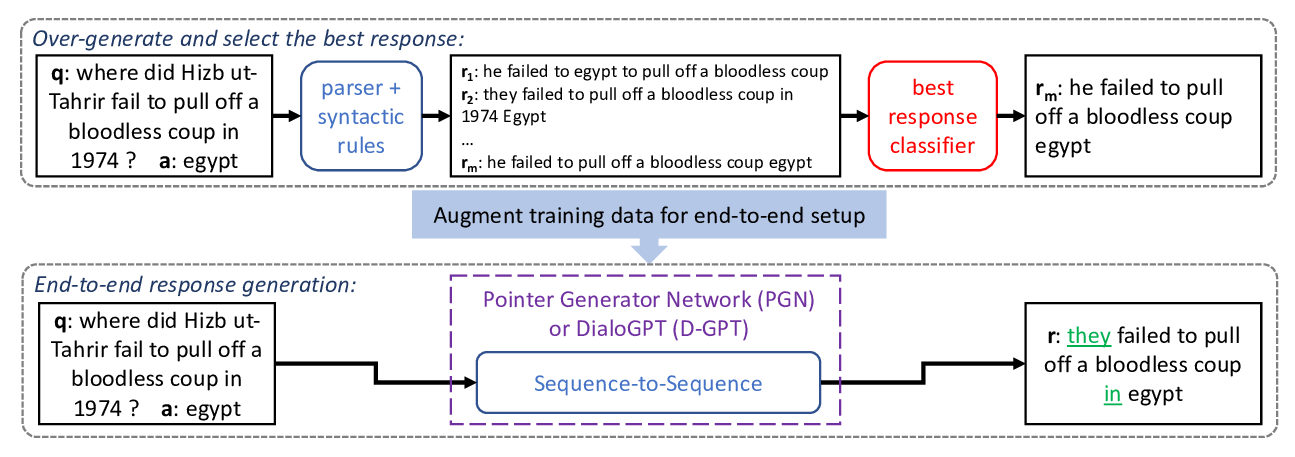
Fluent Response Generation for Conversational Question Answering
Ashutosh Baheti, Alan Ritter, Kevin Small,
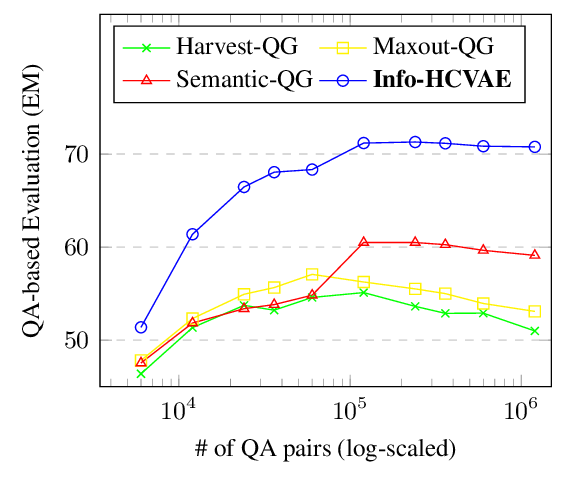
Generating Diverse and Consistent QA pairs from Contexts with Information-Maximizing Hierarchical Conditional VAEs
Dong Bok Lee, Seanie Lee, Woo Tae Jeong, Donghwan Kim, Sung Ju Hwang,