Simple, Interpretable and Stable Method for Detecting Words with Usage Change across Corpora
Hila Gonen, Ganesh Jawahar, Djamé Seddah, Yoav Goldberg
Computational Social Science and Social Media Long Paper
Session 1B: Jul 6
(06:00-07:00 GMT)

Session 2A: Jul 6
(08:00-09:00 GMT)
Abstract:
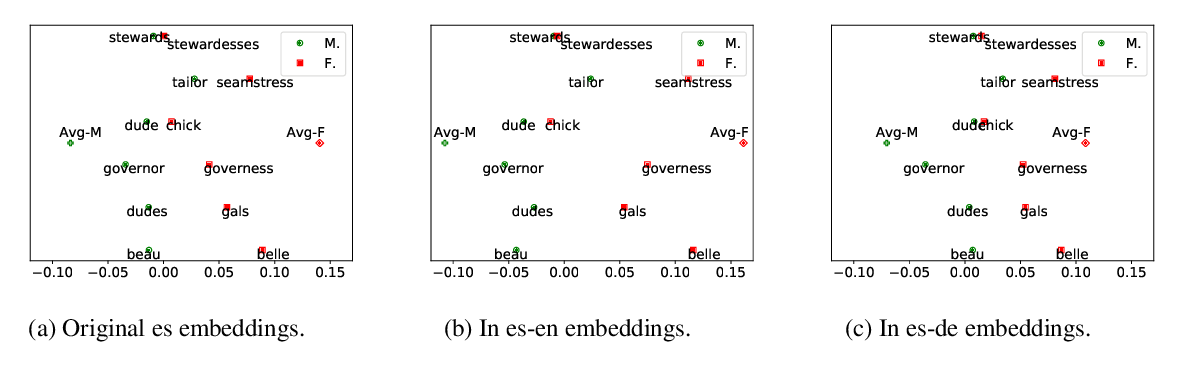
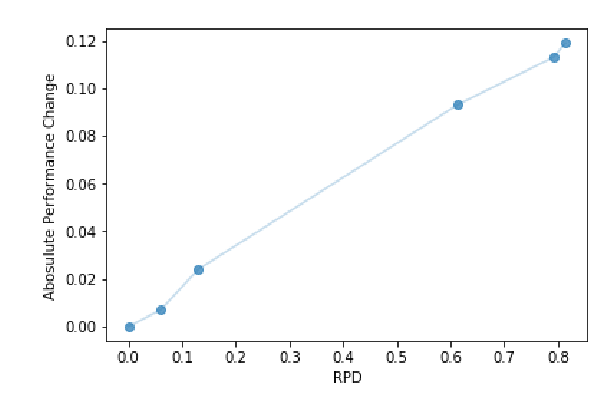
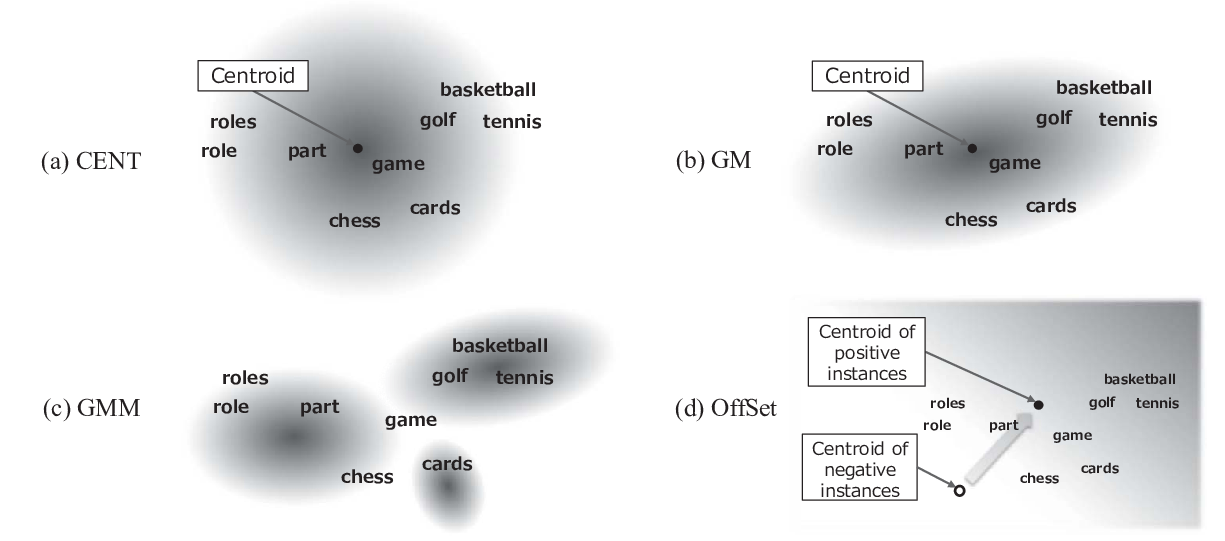
The problem of comparing two bodies of text and searching for words that differ in their usage between them arises often in digital humanities and computational social science. This is commonly approached by training word embeddings on each corpus, aligning the vector spaces, and looking for words whose cosine distance in the aligned space is large. However, these methods often require extensive filtering of the vocabulary to perform well, and - as we show in this work - result in unstable, and hence less reliable, results. We propose an alternative approach that does not use vector space alignment, and instead considers the neighbors of each word. The method is simple, interpretable and stable. We demonstrate its effectiveness in 9 different setups, considering different corpus splitting criteria (age, gender and profession of tweet authors, time of tweet) and different languages (English, French and Hebrew).
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Geometry-aware domain adaptation for unsupervised alignment of word embeddings
Pratik Jawanpuria, Mayank Meghwanshi, Bamdev Mishra,

Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer
Jieyu Zhao, Subhabrata Mukherjee, Saghar Hosseini, Kai-Wei Chang, Ahmed Hassan Awadallah,