Language (Re)modelling: Towards Embodied Language Understanding
Ronen Tamari, Chen Shani, Tom Hope, Miriam R L Petruck, Omri Abend, Dafna Shahaf
Theme Long Paper
Session 11A: Jul 8
(05:00-06:00 GMT)

Session 13B: Jul 8
(13:00-14:00 GMT)
Abstract:
While natural language understanding (NLU) is advancing rapidly, today's technology differs from human-like language understanding in fundamental ways, notably in its inferior efficiency, interpretability, and generalization. This work proposes an approach to representation and learning based on the tenets of embodied cognitive linguistics (ECL). According to ECL, natural language is inherently executable (like programming languages), driven by mental simulation and metaphoric mappings over hierarchical compositions of structures and schemata learned through embodied interaction. This position paper argues that the use of grounding by metaphoric reasoning and simulation will greatly benefit NLU systems, and proposes a system architecture along with a roadmap towards realizing this vision.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
A Generative Model for Joint Natural Language Understanding and Generation
Bo-Hsiang Tseng, Jianpeng Cheng, Yimai Fang, David Vandyke,
Curriculum Learning for Natural Language Understanding
Benfeng Xu, Licheng Zhang, Zhendong Mao, Quan Wang, Hongtao Xie, Yongdong Zhang,
Towards Unsupervised Language Understanding and Generation by Joint Dual Learning
Shang-Yu Su, Chao-Wei Huang, Yun-Nung Chen,
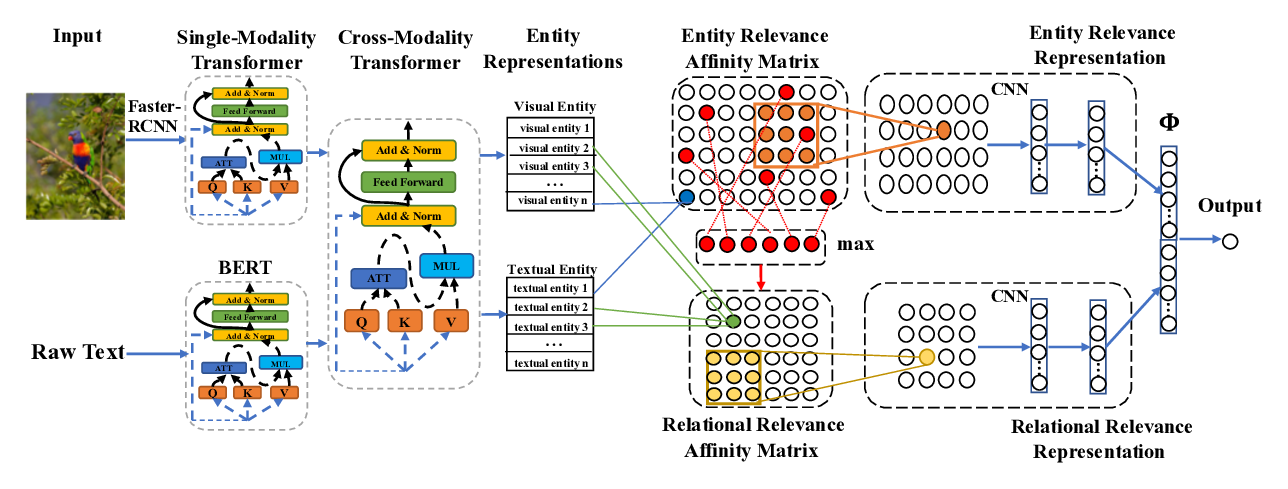
Cross-Modality Relevance for Reasoning on Language and Vision
Chen Zheng, Quan Guo, Parisa Kordjamshidi,