Cross-modal Coherence Modeling for Caption Generation
Malihe Alikhani, Piyush Sharma, Shengjie Li, Radu Soricut, Matthew Stone
Language Grounding to Vision, Robotics and Beyond Long Paper
Session 11B: Jul 8
(06:00-07:00 GMT)

Session 12B: Jul 8
(09:00-10:00 GMT)
Abstract:
We use coherence relations inspired by computational models of discourse to study the information needs and goals of image captioning. Using an annotation protocol specifically devised for capturing image--caption coherence relations, we annotate 10,000 instances from publicly-available image--caption pairs. We introduce a new task for learning inferences in imagery and text, coherence relation prediction, and show that these coherence annotations can be exploited to learn relation classifiers as an intermediary step, and also train coherence-aware, controllable image captioning models. The results show a dramatic improvement in the consistency and quality of the generated captions with respect to information needs specified via coherence relations.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
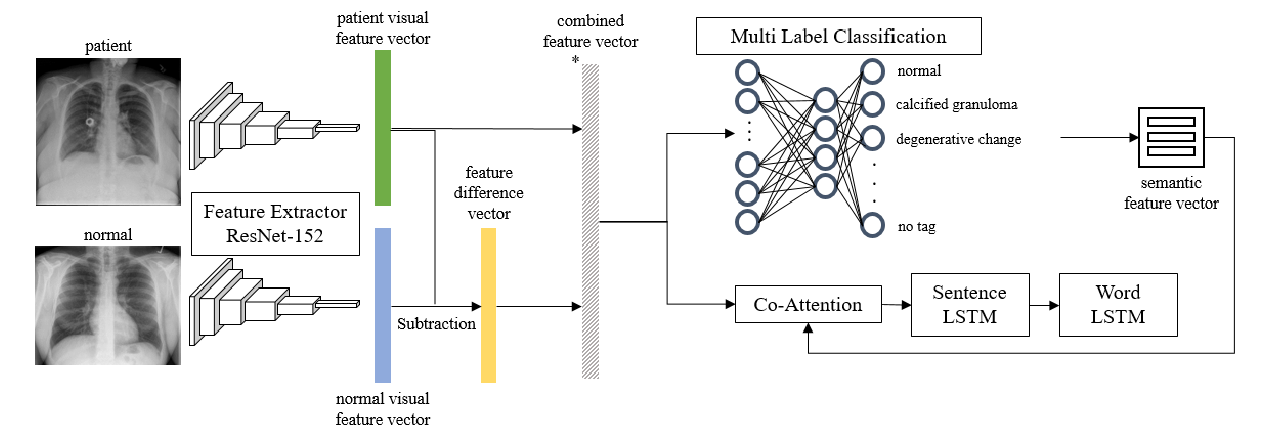
Aligned Dual Channel Graph Convolutional Network for Visual Question Answering
Qingbao Huang, Jielong Wei, Yi Cai, Changmeng Zheng, Junying Chen, Ho-fung Leung, Qing Li,

Non-Topical Coherence in Social Talk: A Call for Dialogue Model Enrichment
Alex Luu, Sophia A. Malamud,
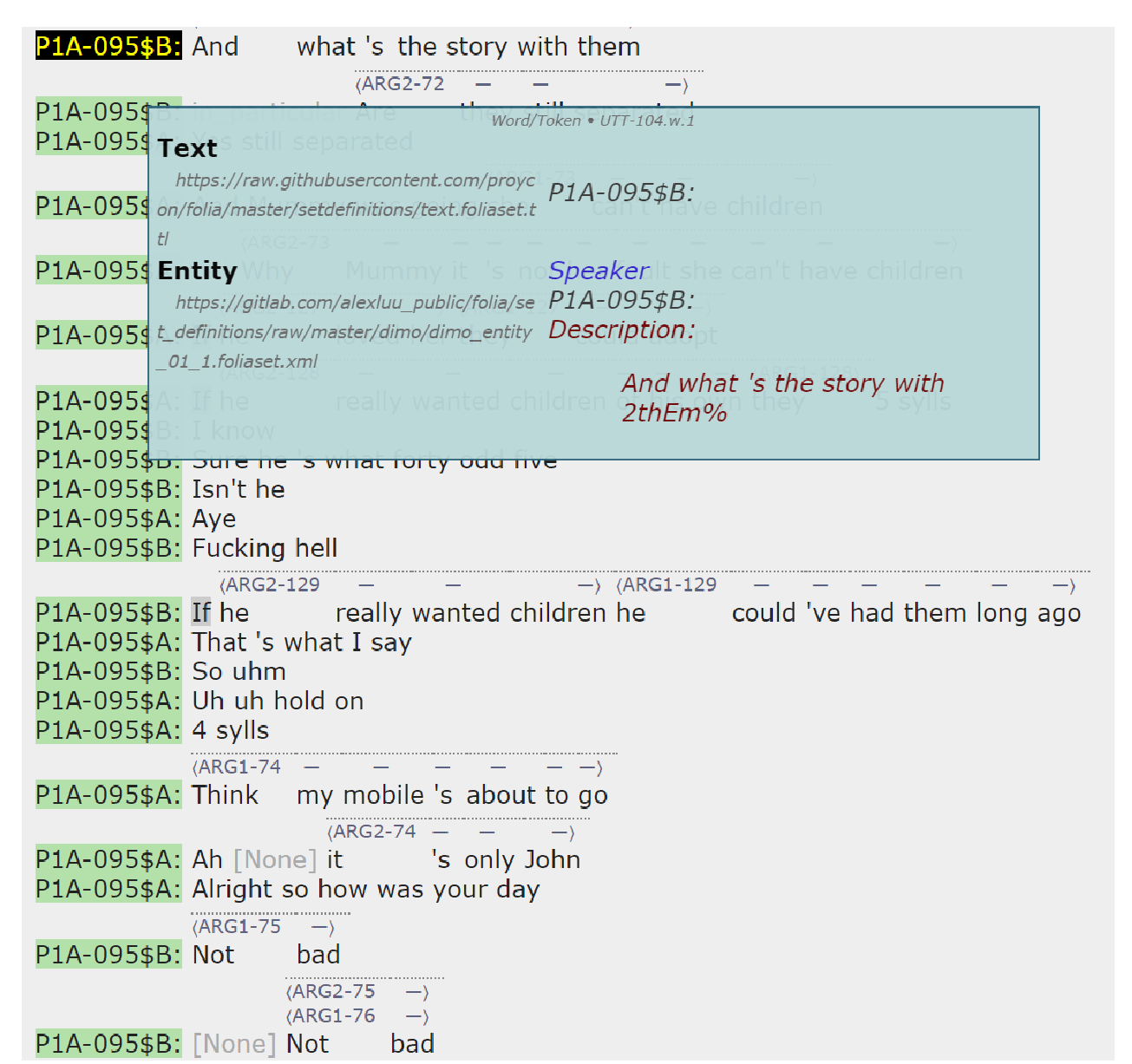
Feature Difference Makes Sense: A medical image captioning model exploiting feature difference and tag information
Hyeryun Park, Kyungmo Kim, Jooyoung Yoon, Seongkeun Park, Jinwook Choi,