Cross-Lingual Semantic Role Labeling with High-Quality Translated Training Corpus
Hao Fei, Meishan Zhang, Donghong Ji
Semantics: Sentence Level Long Paper
Session 12A: Jul 8
(08:00-09:00 GMT)

Session 13A: Jul 8
(12:00-13:00 GMT)
Abstract:
Many efforts of research are devoted to semantic role labeling (SRL) which is crucial for natural language understanding. Supervised approaches have achieved impressing performances when large-scale corpora are available for resource-rich languages such as English. While for the low-resource languages with no annotated SRL dataset, it is still challenging to obtain competitive performances. Cross-lingual SRL is one promising way to address the problem, which has achieved great advances with the help of model transferring and annotation projection. In this paper, we propose a novel alternative based on corpus translation, constructing high-quality training datasets for the target languages from the source gold-standard SRL annotations. Experimental results on Universal Proposition Bank show that the translation-based method is highly effective, and the automatic pseudo datasets can improve the target-language SRL performances significantly.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Single-/Multi-Source Cross-Lingual NER via Teacher-Student Learning on Unlabeled Data in Target Language
Qianhui Wu, Zijia Lin, Börje Karlsson, Jian-Guang Lou, Biqing Huang,
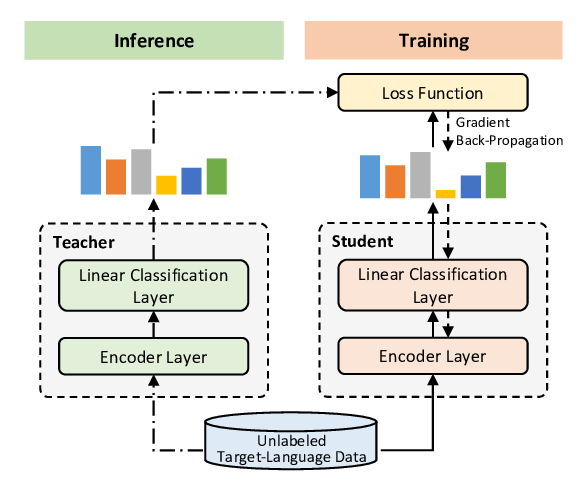
Hypernymy Detection for Low-Resource Languages via Meta Learning
Changlong Yu, Jialong Han, Haisong Zhang, Wilfred Ng,
Improving Candidate Generation for Low-resource Cross-lingual Entity Linking
Shuyan Zhou, Shruti Rijhwani, John Wieting, Jaime Carbonell, Graham Neubig,
Learning to Contextually Aggregate Multi-Source Supervision for Sequence Labeling
Ouyu Lan, Xiao Huang, Bill Yuchen Lin, He Jiang, Liyuan Liu, Xiang Ren,