Refer360°: A Referring Expression Recognition Dataset in 360° Images
Volkan Cirik, Taylor Berg-Kirkpatrick, Louis-Philippe Morency
Language Grounding to Vision, Robotics and Beyond Long Paper
Session 12B: Jul 8
(09:00-10:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
We propose a novel large-scale referring expression recognition dataset, Refer360°, consisting of 17,137 instruction sequences and ground-truth actions for completing these instructions in 360° scenes. Refer360° differs from existing related datasets in three ways. First, we propose a more realistic scenario where instructors and the followers have partial, yet dynamic, views of the scene – followers continuously modify their field-of-view (FoV) while interpreting instructions that specify a final target location. Second, instructions to find the target location consist of multiple steps for followers who will start at random FoVs. As a result, intermediate instructions are strongly grounded in object references, and followers must identify intermediate FoVs to find the final target location correctly. Third, the target locations are neither restricted to predefined objects nor chosen by annotators; instead, they are distributed randomly across scenes. This “point anywhere” approach leads to more linguistically complex instructions, as shown in our analyses. Our examination of the dataset shows that Refer360° manifests linguistically rich phenomena in a language grounding task that poses novel challenges for computational modeling of language, vision, and navigation.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Mapping Natural Language Instructions to Mobile UI Action Sequences
Yang Li, Jiacong He, Xin Zhou, Yuan Zhang, Jason Baldridge,
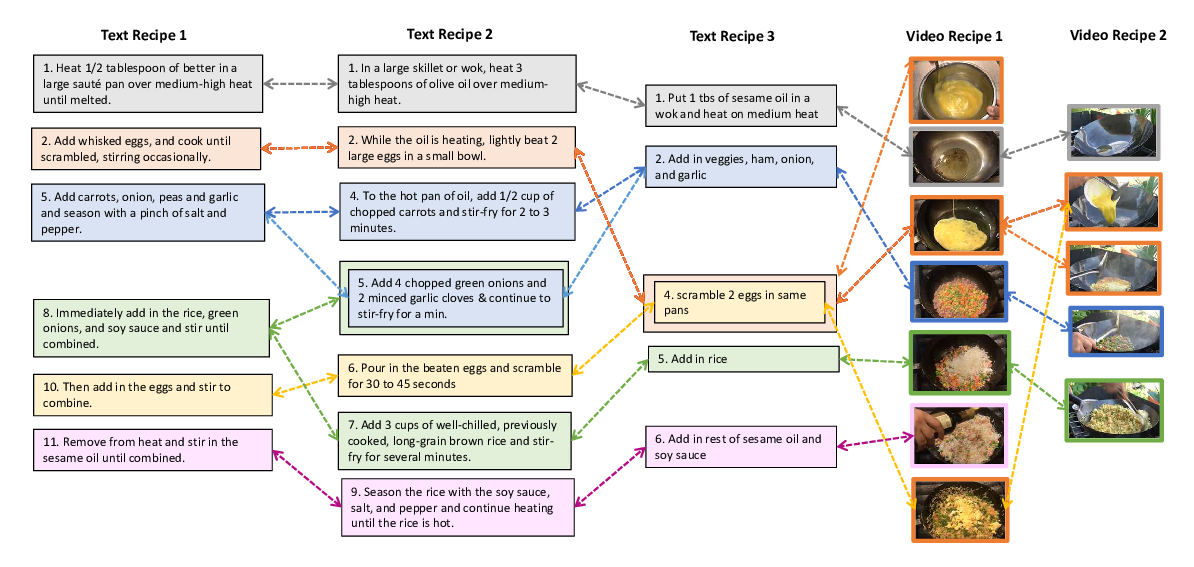
A Recipe for Creating Multimodal Aligned Datasets for Sequential Tasks
Angela Lin, Sudha Rao, Asli Celikyilmaz, Elnaz Nouri, Chris Brockett, Debadeepta Dey, Bill Dolan,
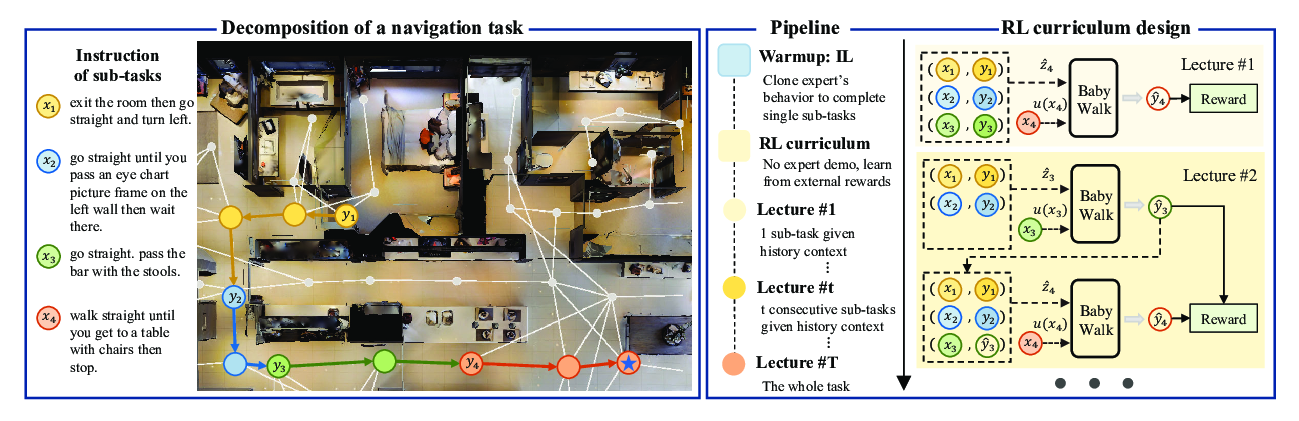
BabyWalk: Going Farther in Vision-and-Language Navigation by Taking Baby Steps
Wang Zhu, Hexiang Hu, Jiacheng Chen, Zhiwei Deng, Vihan Jain, Eugene Ie, Fei Sha,
Target-Guided Structured Attention Network for Target-dependent Sentiment Analysis
Ji Zhang, Chengyao Chen, Pengfei Liu, Chao He, Cane Wing-Ki Leung,