Mapping Natural Language Instructions to Mobile UI Action Sequences
Yang Li, Jiacong He, Xin Zhou, Yuan Zhang, Jason Baldridge
Language Grounding to Vision, Robotics and Beyond Long Paper
Session 14A: Jul 8
(17:00-18:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
We present a new problem: grounding natural language instructions to mobile user interface actions, and contribute three new datasets for it. For full task evaluation, we create PixelHelp, a corpus that pairs English instructions with actions performed by people on a mobile UI emulator. To scale training, we decouple the language and action data by (a) annotating action phrase spans in How-To instructions and (b) synthesizing grounded descriptions of actions for mobile user interfaces. We use a Transformer to extract action phrase tuples from long-range natural language instructions. A grounding Transformer then contextually represents UI objects using both their content and screen position and connects them to object descriptions. Given a starting screen and instruction, our model achieves 70.59% accuracy on predicting complete ground-truth action sequences in PixelHelp.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Refer360°: A Referring Expression Recognition Dataset in 360° Images
Volkan Cirik, Taylor Berg-Kirkpatrick, Louis-Philippe Morency,

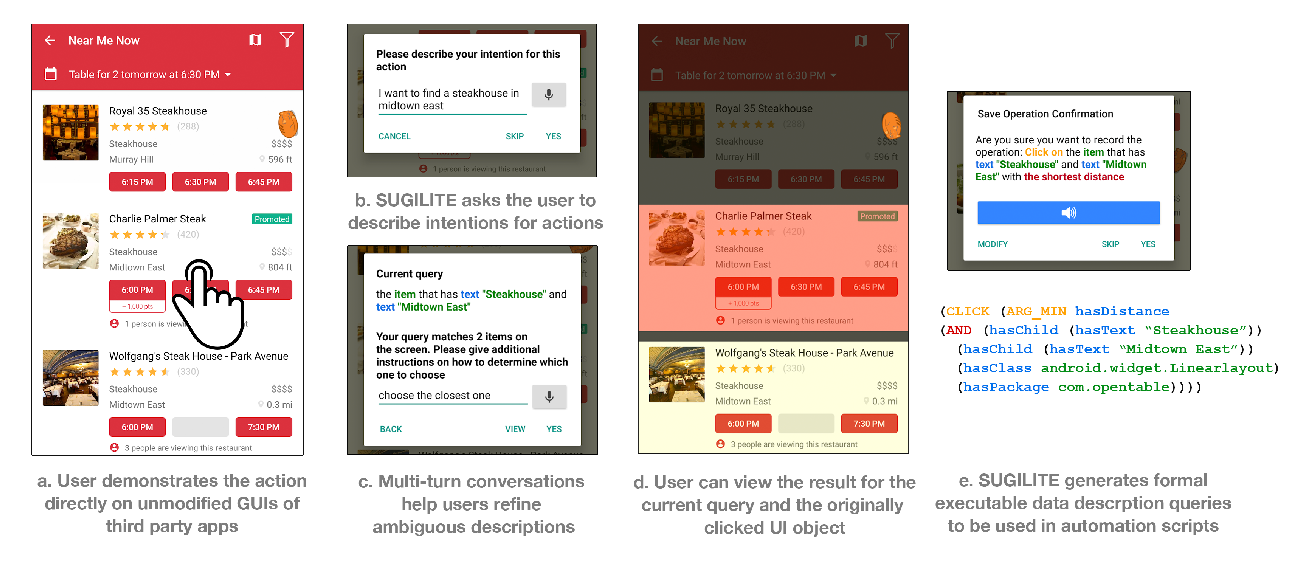
Interactive Task Learning from GUI-Grounded Natural Language Instructions and Demonstrations
Toby Jia-Jun Li, Tom Mitchell, Brad Myers,
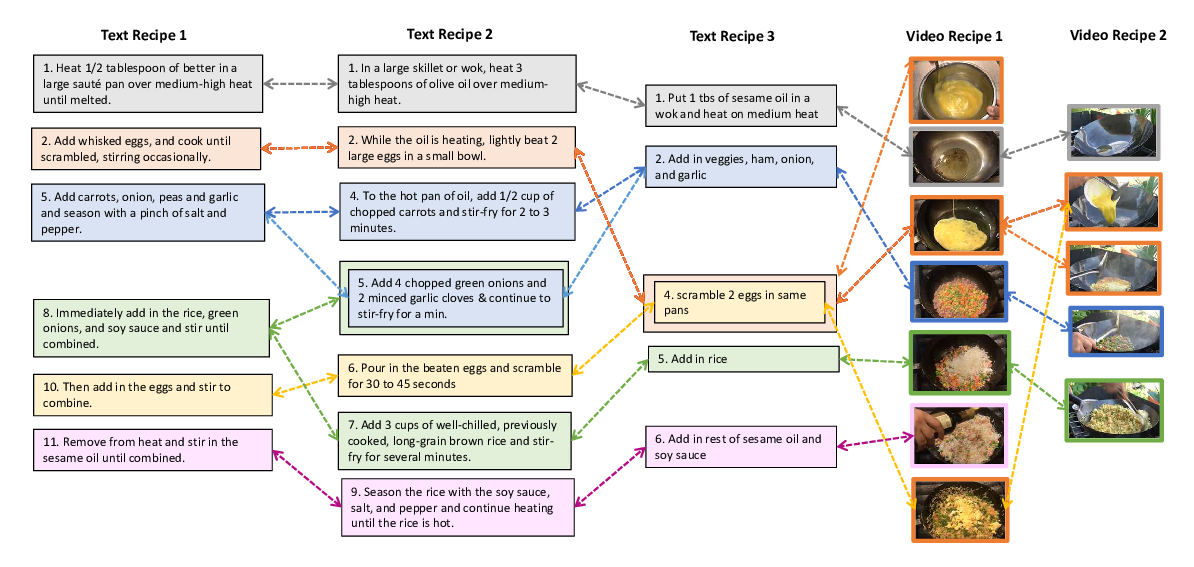
A Recipe for Creating Multimodal Aligned Datasets for Sequential Tasks
Angela Lin, Sudha Rao, Asli Celikyilmaz, Elnaz Nouri, Chris Brockett, Debadeepta Dey, Bill Dolan,
Learning to execute instructions in a Minecraft dialogue
Prashant Jayannavar, Anjali Narayan-Chen, Julia Hockenmaier,