A Recipe for Creating Multimodal Aligned Datasets for Sequential Tasks
Angela Lin, Sudha Rao, Asli Celikyilmaz, Elnaz Nouri, Chris Brockett, Debadeepta Dey, Bill Dolan
Resources and Evaluation Long Paper
Session 9A: Jul 7
(17:00-18:00 GMT)

Session 10B: Jul 7
(21:00-22:00 GMT)
Abstract:
Many high-level procedural tasks can be decomposed into sequences of instructions that vary in their order and choice of tools. In the cooking domain, the web offers many, partially-overlapping, text and video recipes (i.e. procedures) that describe how to make the same dish (i.e. high-level task). Aligning instructions for the same dish across different sources can yield descriptive visual explanations that are far richer semantically than conventional textual instructions, providing commonsense insight into how real-world procedures are structured. Learning to align these different instruction sets is challenging because: a) different recipes vary in their order of instructions and use of ingredients; and b) video instructions can be noisy and tend to contain far more information than text instructions. To address these challenges, we use an unsupervised alignment algorithm that learns pairwise alignments between instructions of different recipes for the same dish. We then use a graph algorithm to derive a joint alignment between multiple text and multiple video recipes for the same dish. We release the Microsoft Research Multimodal Aligned Recipe Corpus containing ~150K pairwise alignments between recipes across 4262 dishes with rich commonsense information.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Mapping Natural Language Instructions to Mobile UI Action Sequences
Yang Li, Jiacong He, Xin Zhou, Yuan Zhang, Jason Baldridge,
Refer360°: A Referring Expression Recognition Dataset in 360° Images
Volkan Cirik, Taylor Berg-Kirkpatrick, Louis-Philippe Morency,

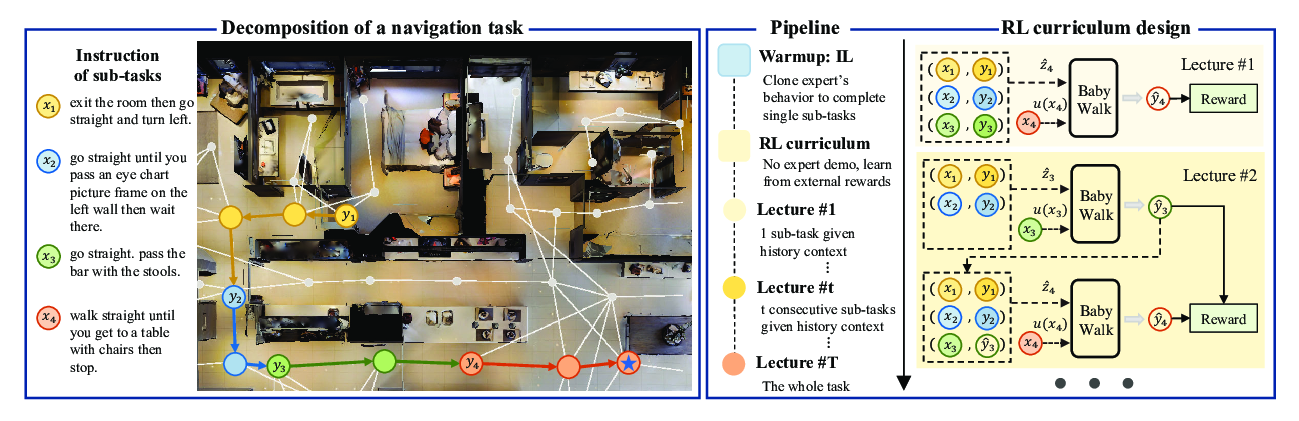
BabyWalk: Going Farther in Vision-and-Language Navigation by Taking Baby Steps
Wang Zhu, Hexiang Hu, Jiacheng Chen, Zhiwei Deng, Vihan Jain, Eugene Ie, Fei Sha,
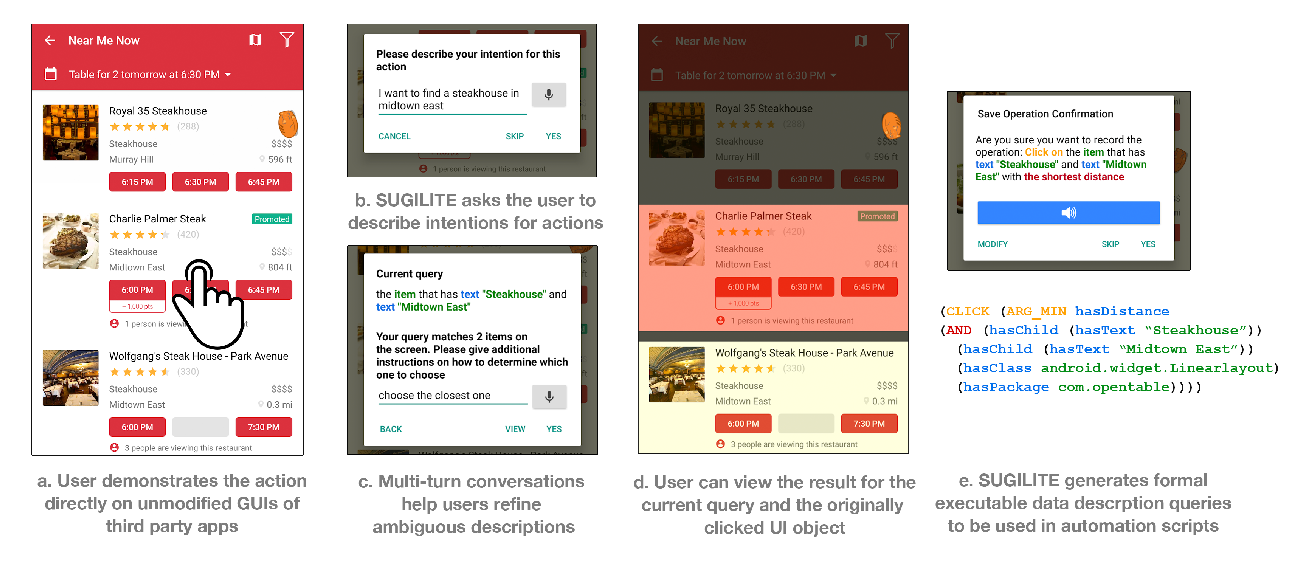
Interactive Task Learning from GUI-Grounded Natural Language Instructions and Demonstrations
Toby Jia-Jun Li, Tom Mitchell, Brad Myers,