MLQA: Evaluating Cross-lingual Extractive Question Answering
Patrick Lewis, Barlas Oguz, Ruty Rinott, Sebastian Riedel, Holger Schwenk
Question Answering Long Paper
Session 12B: Jul 8
(09:00-10:00 GMT)

Session 13B: Jul 8
(13:00-14:00 GMT)
Abstract:
Question answering (QA) models have shown rapid progress enabled by the availability of large, high-quality benchmark datasets. Such annotated datasets are difficult and costly to collect, and rarely exist in languages other than English, making building QA systems that work well in other languages challenging. In order to develop such systems, it is crucial to invest in high quality multilingual evaluation benchmarks to measure progress. We present MLQA, a multi-way aligned extractive QA evaluation benchmark intended to spur research in this area. MLQA contains QA instances in 7 languages, English, Arabic, German, Spanish, Hindi, Vietnamese and Simplified Chinese. MLQA has over 12K instances in English and 5K in each other language, with each instance parallel between 4 languages on average. We evaluate state-of-the-art cross-lingual models and machine-translation-based baselines on MLQA. In all cases, transfer results are shown to be significantly behind training-language performance.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Template-Based Question Generation from Retrieved Sentences for Improved Unsupervised Question Answering
Alexander Fabbri, Patrick Ng, Zhiguo Wang, Ramesh Nallapati, Bing Xiang,
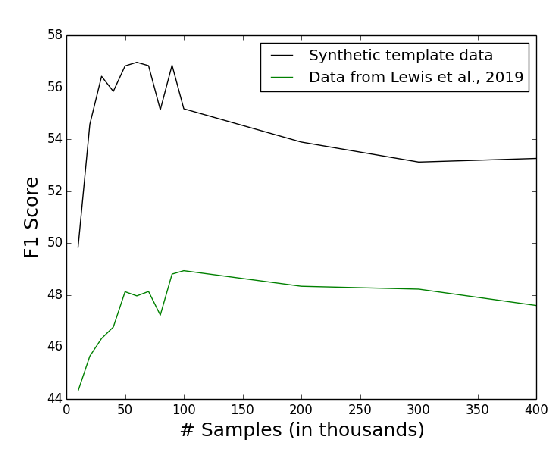
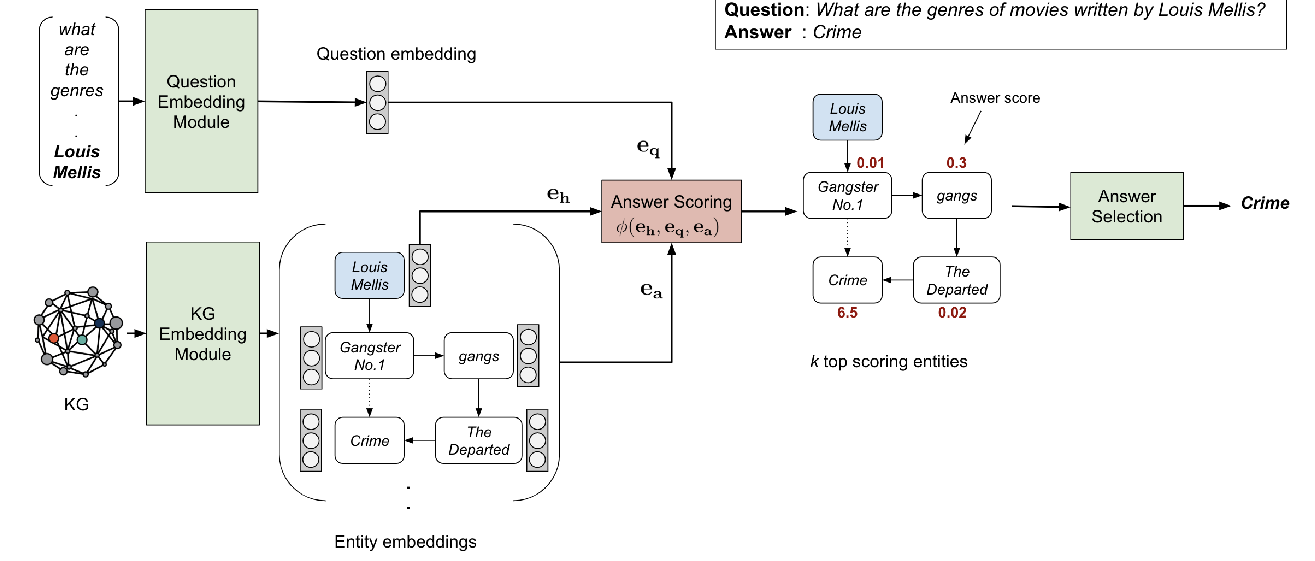
Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings
Apoorv Saxena, Aditay Tripathi, Partha Talukdar,
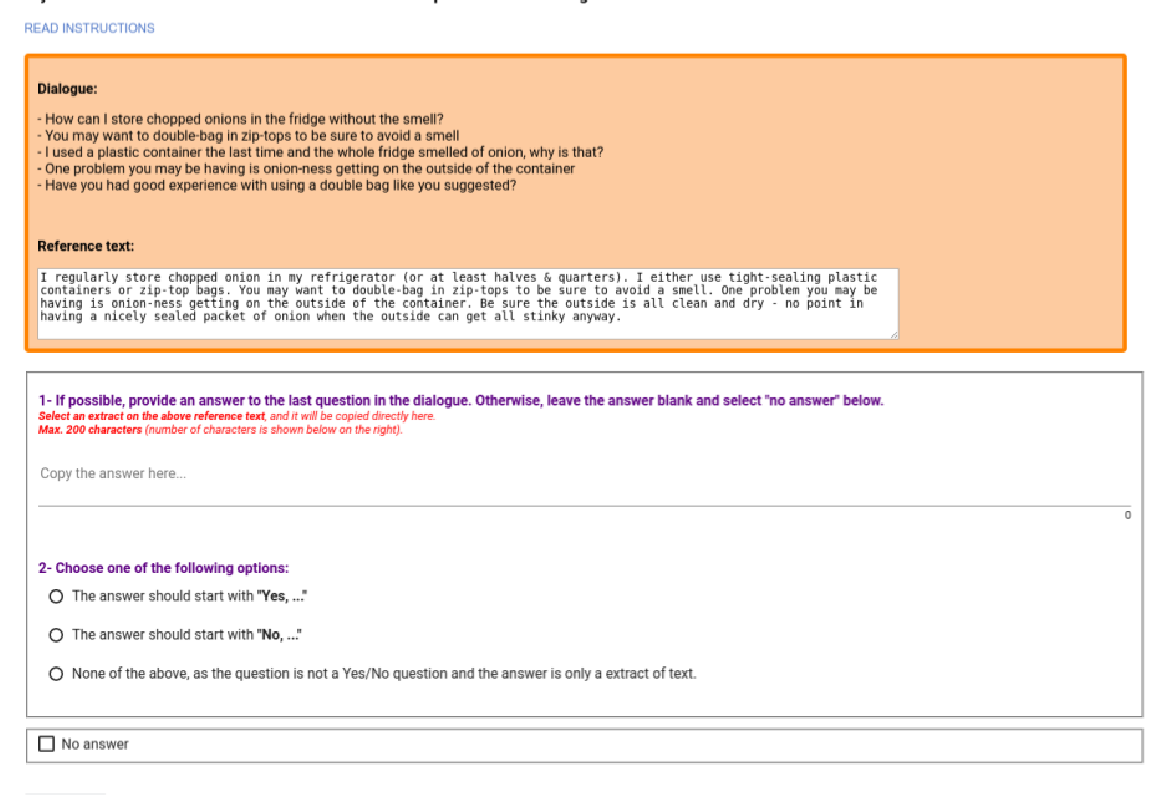
DoQA - Accessing Domain-Specific FAQs via Conversational QA
Jon Ander Campos, Arantxa Otegi, Aitor Soroa, Jan Deriu, Mark Cieliebak, Eneko Agirre,
Harvesting and Refining Question-Answer Pairs for Unsupervised QA
Zhongli Li, Wenhui Wang, Li Dong, Furu Wei, Ke Xu,
