HAT: Hardware-Aware Transformers for Efficient Natural Language Processing
Hanrui Wang, Zhanghao Wu, Zhijian Liu, Han Cai, Ligeng Zhu, Chuang Gan, Song Han
Machine Translation Long Paper
Session 13B: Jul 8
(13:00-14:00 GMT)

Session 15B: Jul 8
(21:00-22:00 GMT)
Abstract:
Transformers are ubiquitous in Natural Language Processing (NLP) tasks, but they are difficult to be deployed on hardware due to the intensive computation. To enable low-latency inference on resource-constrained hardware platforms, we propose to design Hardware-Aware Transformers (HAT) with neural architecture search. We first construct a large design space with arbitrary encoder-decoder attention and heterogeneous layers. Then we train a SuperTransformer that covers all candidates in the design space, and efficiently produces many SubTransformers with weight sharing. Finally, we perform an evolutionary search with a hardware latency constraint to find a specialized SubTransformer dedicated to run fast on the target hardware. Extensive experiments on four machine translation tasks demonstrate that HAT can discover efficient models for different hardware (CPU, GPU, IoT device). When running WMT’14 translation task on Raspberry Pi-4, HAT can achieve 3× speedup, 3.7× smaller size over baseline Transformer; 2.7× speedup, 3.6× smaller size over Evolved Transformer with 12,041× less search cost and no performance loss. HAT is open-sourced at https://github.com/mit-han-lab/hardware-aware-transformers.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
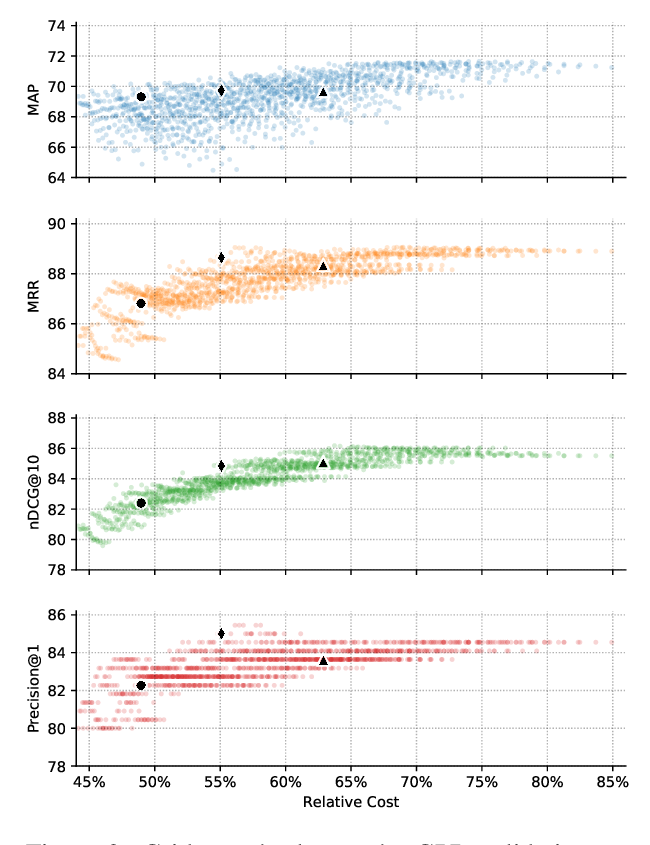
DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference
Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, Jimmy Lin,
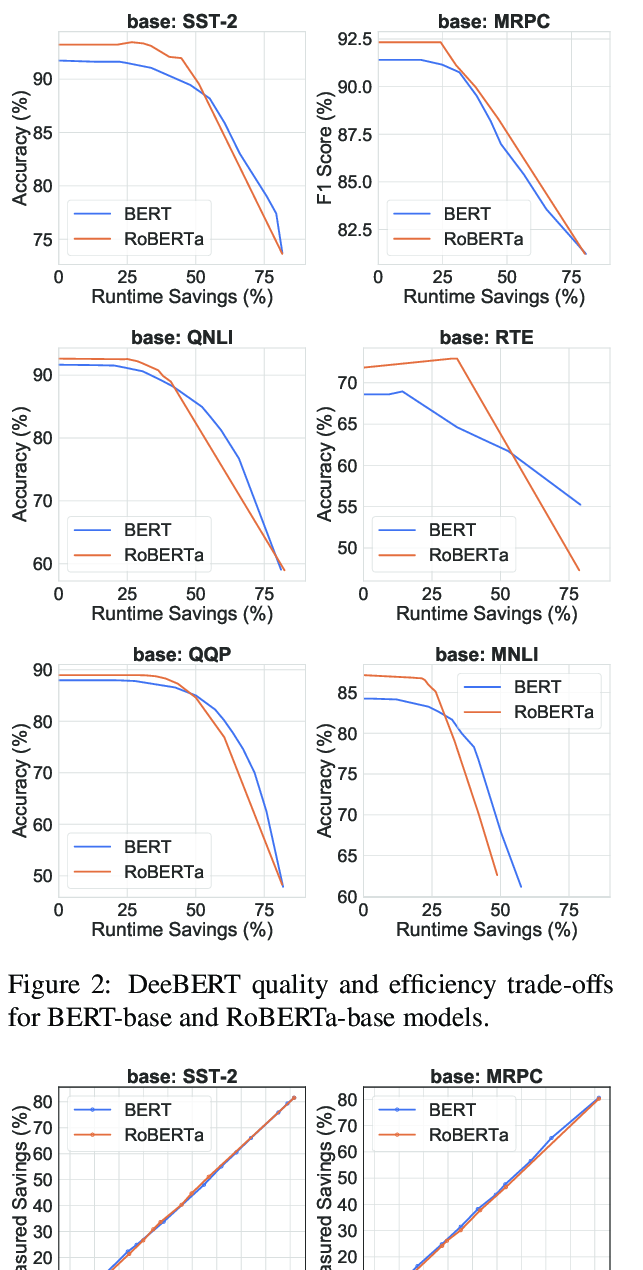
DeFormer: Decomposing Pre-trained Transformers for Faster Question Answering
Qingqing Cao, Harsh Trivedi, Aruna Balasubramanian, Niranjan Balasubramanian,
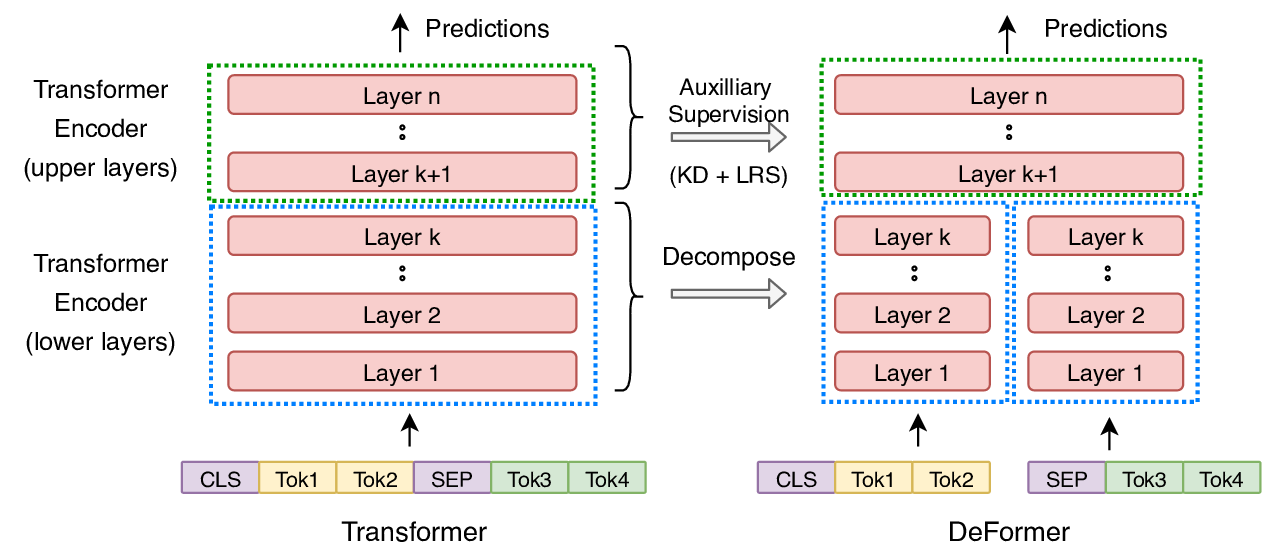
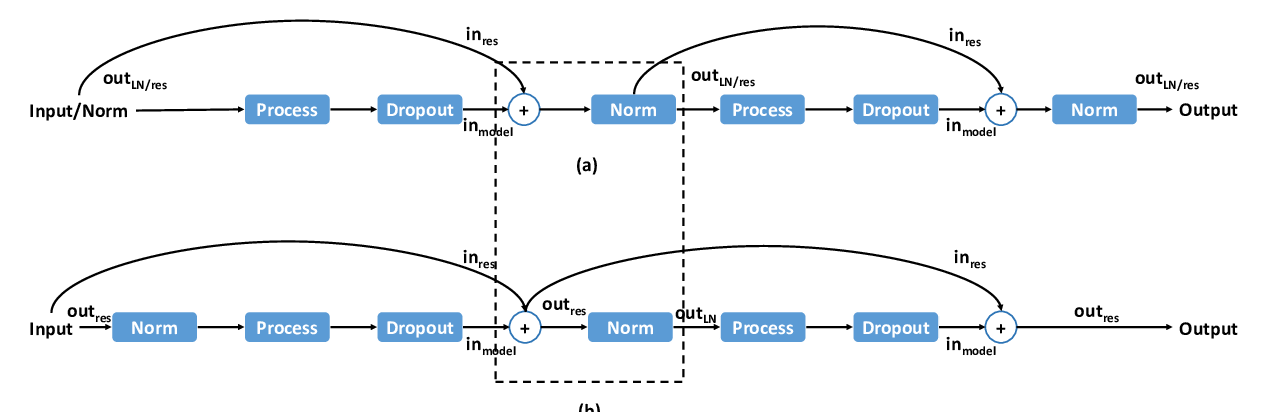
Lipschitz Constrained Parameter Initialization for Deep Transformers
Hongfei Xu, Qiuhui Liu, Josef van Genabith, Deyi Xiong, Jingyi Zhang,
The Cascade Transformer: an Application for Efficient Answer Sentence Selection
Luca Soldaini, Alessandro Moschitti,