Revisiting the Context Window for Cross-lingual Word Embeddings
Ryokan Ri, Yoshimasa Tsuruoka
Resources and Evaluation Long Paper
Session 1B: Jul 6
(06:00-07:00 GMT)

Session 2B: Jul 6
(09:00-10:00 GMT)
Abstract:
Existing approaches to mapping-based cross-lingual word embeddings are based on the assumption that the source and target embedding spaces are structurally similar. The structures of embedding spaces largely depend on the co-occurrence statistics of each word, which the choice of context window determines. Despite this obvious connection between the context window and mapping-based cross-lingual embeddings, their relationship has been underexplored in prior work. In this work, we provide a thorough evaluation, in various languages, domains, and tasks, of bilingual embeddings trained with different context windows. The highlight of our findings is that increasing the size of both the source and target window sizes improves the performance of bilingual lexicon induction, especially the performance on frequent nouns.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
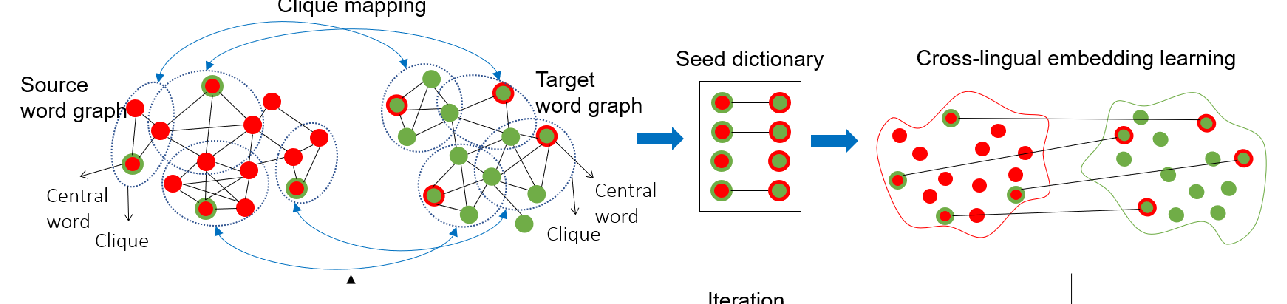
A Graph-based Coarse-to-fine Method for Unsupervised Bilingual Lexicon Induction
Shuo Ren, Shujie Liu, Ming Zhou, Shuai Ma,
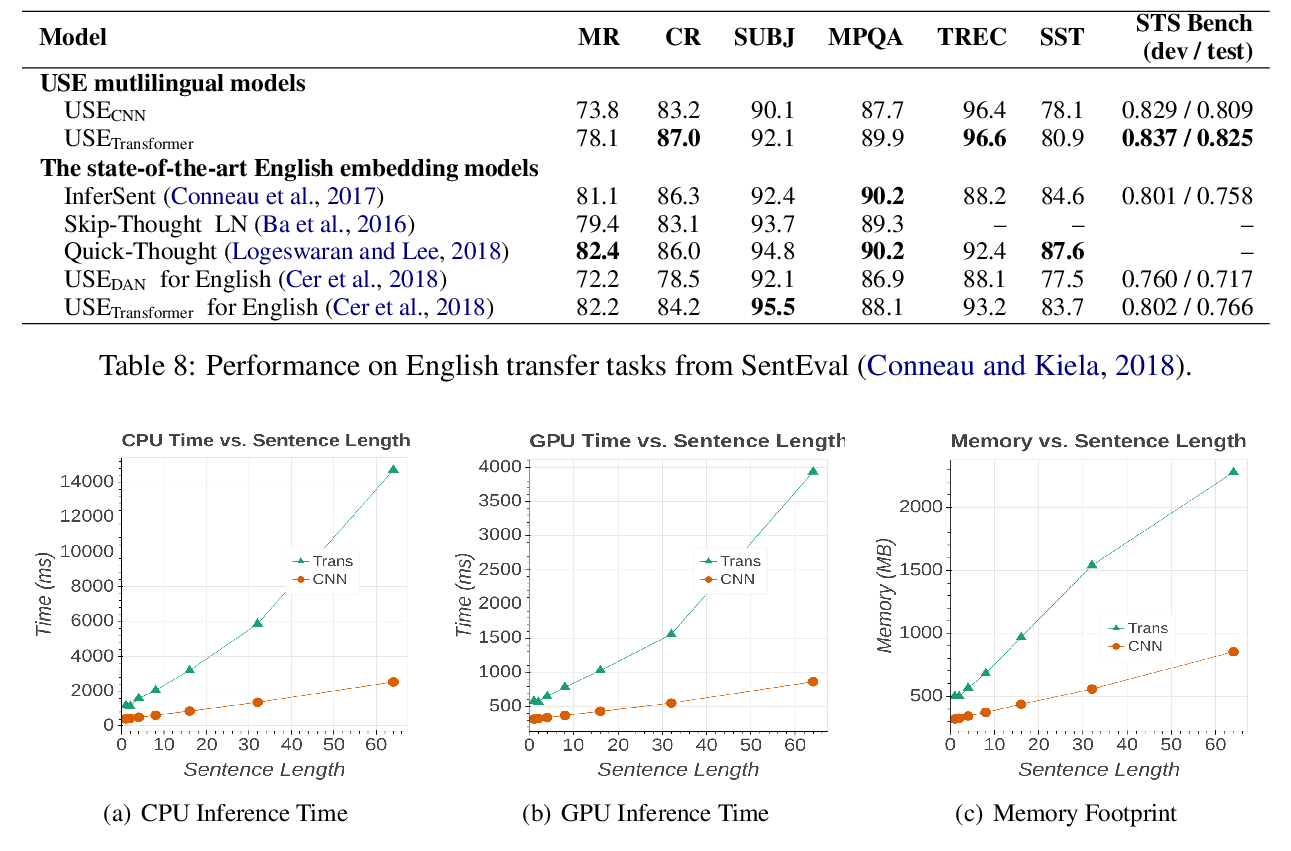
Multilingual Universal Sentence Encoder for Semantic Retrieval
Yinfei Yang, Daniel Cer, Amin Ahmad, Mandy Guo, Jax Law, Noah Constant, Gustavo Hernandez Abrego, Steve Yuan, Chris Tar, Yun-hsuan Sung, Brian Strope, Ray Kurzweil,
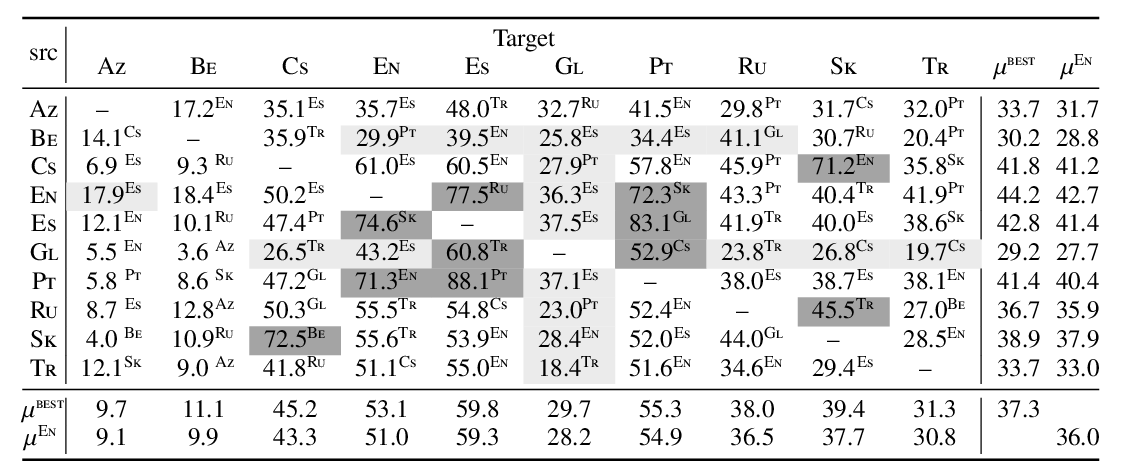
A Monolingual Approach to Contextualized Word Embeddings for Mid-Resource Languages
Pedro Javier Ortiz Suárez, Laurent Romary, Benoît Sagot,