Better Document-level Machine Translation with Bayes' Rule
Lei Yu, Laurent Sartran, Wojciech Stokowiec, Wang Ling, Lingpeng Kong, Phil Blunsom, Chris Dyer
Machine Translation TACL Paper
Session 7A: Jul 7
(08:00-09:00 GMT)

Session 8B: Jul 7
(13:00-14:00 GMT)
Abstract:
We show that Bayes' rule provides an effective mechanism for creating document translation models that can be learned from only parallel sentences and monolingual documents---a compelling benefit as parallel documents are not always available. In our formulation, the posterior probability of a candidate translation is the product of the unconditional (prior) probability of the candidate output document and the ``reverse translation probability'' of translating the candidate output back into the source language. Our proposed model uses a powerful autoregressive language model as the prior on target language documents, but it assumes that each sentence is translated independently from the target to the source language. Crucially, at test time, when a source document is observed, the document language model prior induces dependencies between the translations of the source sentences in the posterior. The model's independence assumption not only enables efficient use of available data, but it additionally admits a practical left-to-right beam-search algorithm for carrying out inference. Experiments show that our model benefits from using cross-sentence context in the language model, and it outperforms existing document translation approaches.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
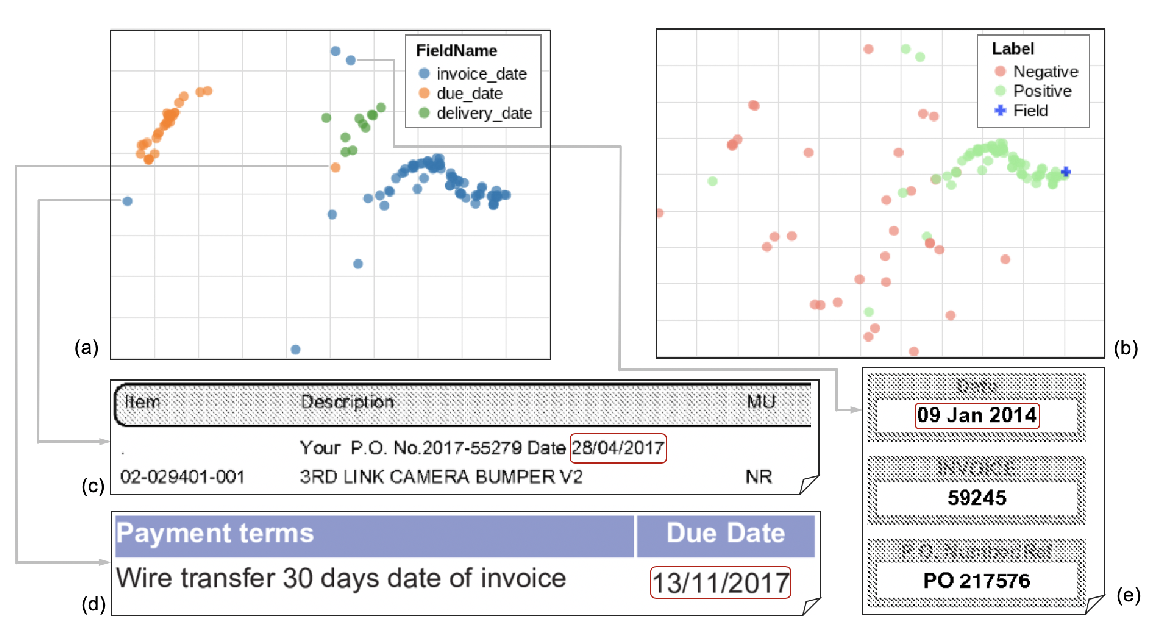
Representation Learning for Information Extraction from Form-like Documents
Bodhisattwa Prasad Majumder, Navneet Potti, Sandeep Tata, James Bradley Wendt, Qi Zhao, Marc Najork,
SPECTER: Document-level Representation Learning using Citation-informed Transformers
Arman Cohan, Sergey Feldman, Iz Beltagy, Doug Downey, Daniel Weld,

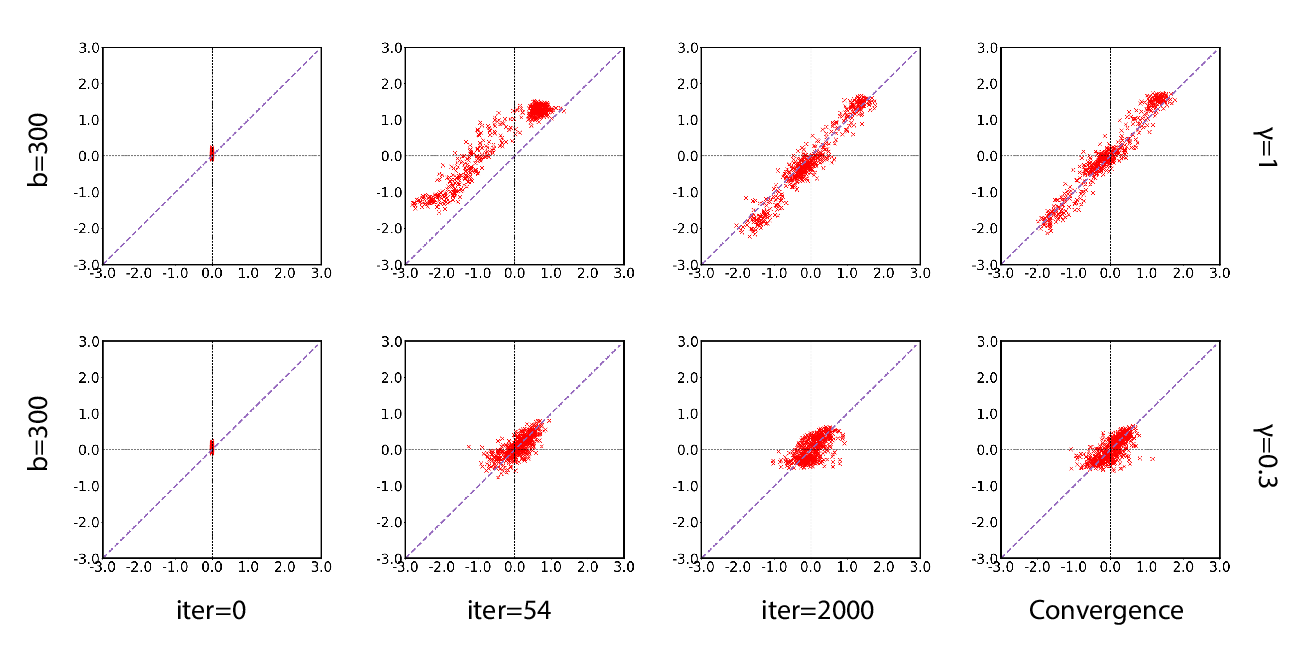
A Batch Normalized Inference Network Keeps the KL Vanishing Away
Qile Zhu, Wei Bi, Xiaojiang Liu, Xiyao Ma, Xiaolin Li, Dapeng Wu,
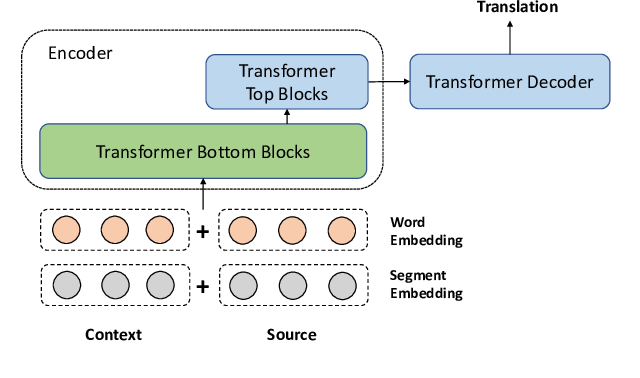
A Simple and Effective Unified Encoder for Document-Level Machine Translation
Shuming Ma, Dongdong Zhang, Ming Zhou,