Is Your Classifier Actually Biased? Measuring Fairness under Uncertainty with Bernstein Bounds
Kawin Ethayarajh
Ethics and NLP Short Paper
Session 6A: Jul 7
(05:00-06:00 GMT)

Session 7B: Jul 7
(09:00-10:00 GMT)
Abstract:
Most NLP datasets are not annotated with protected attributes such as gender, making it difficult to measure classification bias using standard measures of fairness (e.g., equal opportunity). However, manually annotating a large dataset with a protected attribute is slow and expensive. Instead of annotating all the examples, can we annotate a subset of them and use that sample to estimate the bias? While it is possible to do so, the smaller this annotated sample is, the less certain we are that the estimate is close to the true bias. In this work, we propose using Bernstein bounds to represent this uncertainty about the bias estimate as a confidence interval. We provide empirical evidence that a 95% confidence interval derived this way consistently bounds the true bias. In quantifying this uncertainty, our method, which we call Bernstein-bounded unfairness, helps prevent classifiers from being deemed biased or unbiased when there is insufficient evidence to make either claim. Our findings suggest that the datasets currently used to measure specific biases are too small to conclusively identify bias except in the most egregious cases. For example, consider a co-reference resolution system that is 5% more accurate on gender-stereotypical sentences -- to claim it is biased with 95% confidence, we need a bias-specific dataset that is 3.8 times larger than WinoBias, the largest available.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
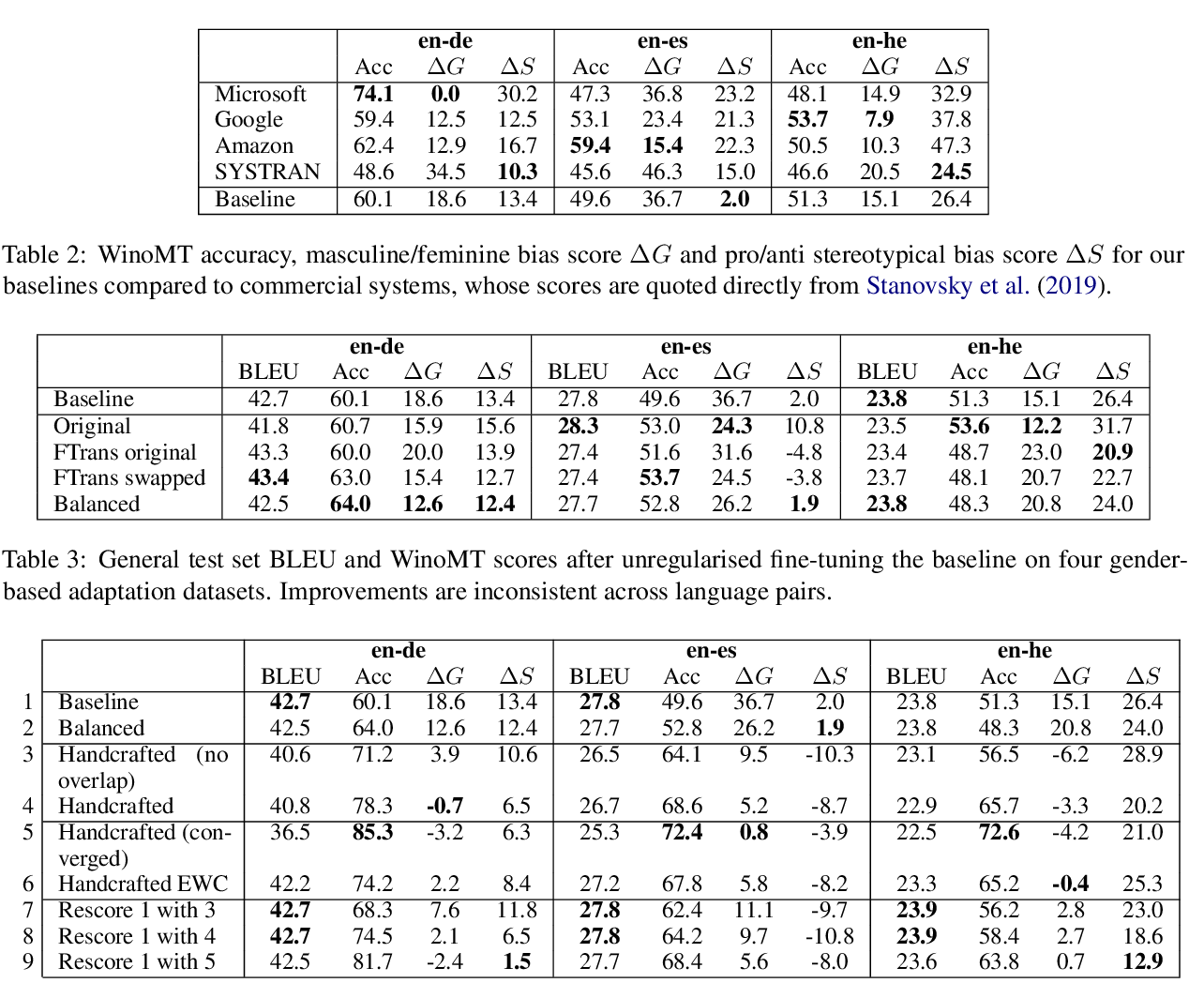
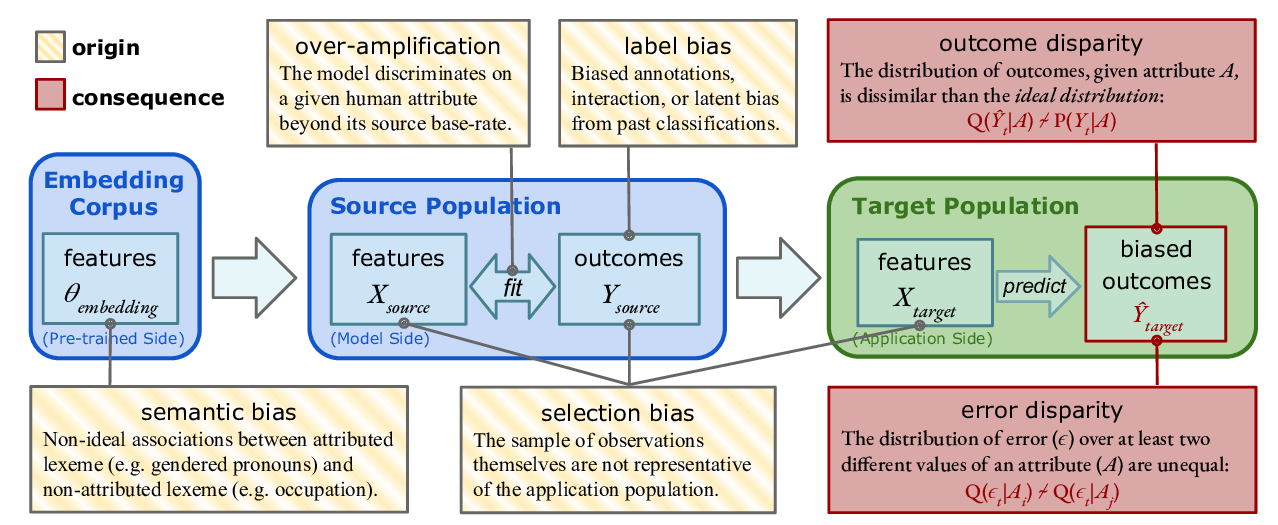
Predictive Biases in Natural Language Processing Models: A Conceptual Framework and Overview
Deven Santosh Shah, H. Andrew Schwartz, Dirk Hovy,
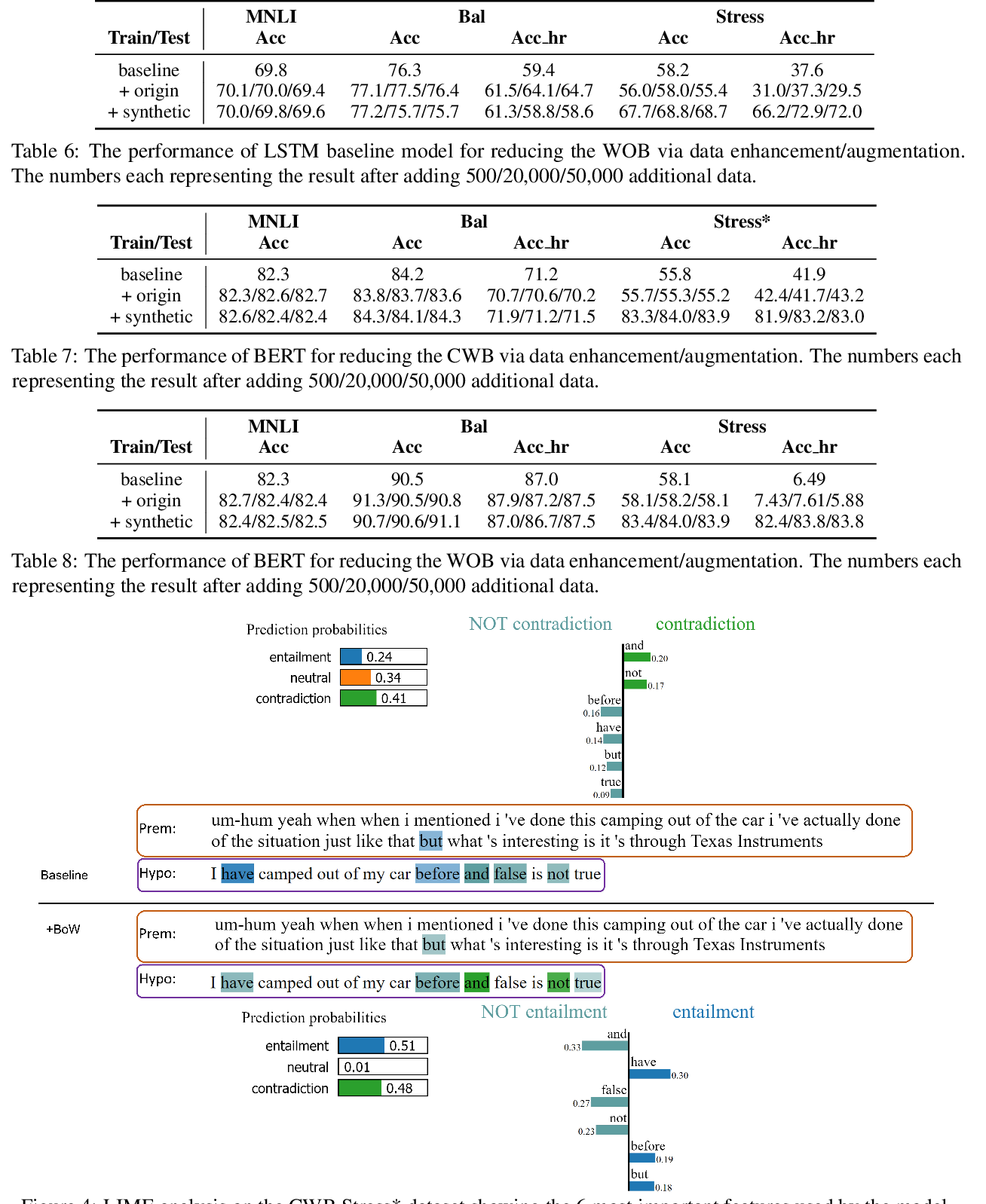
Mitigating Gender Bias Amplification in Distribution by Posterior Regularization
Shengyu Jia, Tao Meng, Jieyu Zhao, Kai-Wei Chang,
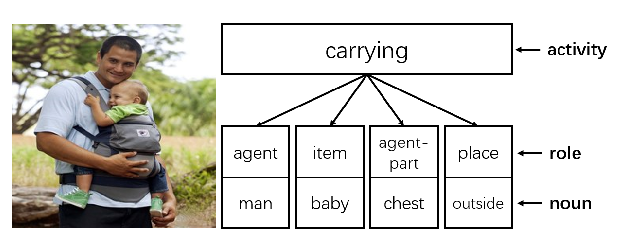
Reducing Gender Bias in Neural Machine Translation as a Domain Adaptation Problem
Danielle Saunders, Bill Byrne,