Predictive Biases in Natural Language Processing Models: A Conceptual Framework and Overview
Deven Santosh Shah, H. Andrew Schwartz, Dirk Hovy
Theme Long Paper
Session 9A: Jul 7
(17:00-18:00 GMT)

Session 10A: Jul 7
(20:00-21:00 GMT)
Abstract:
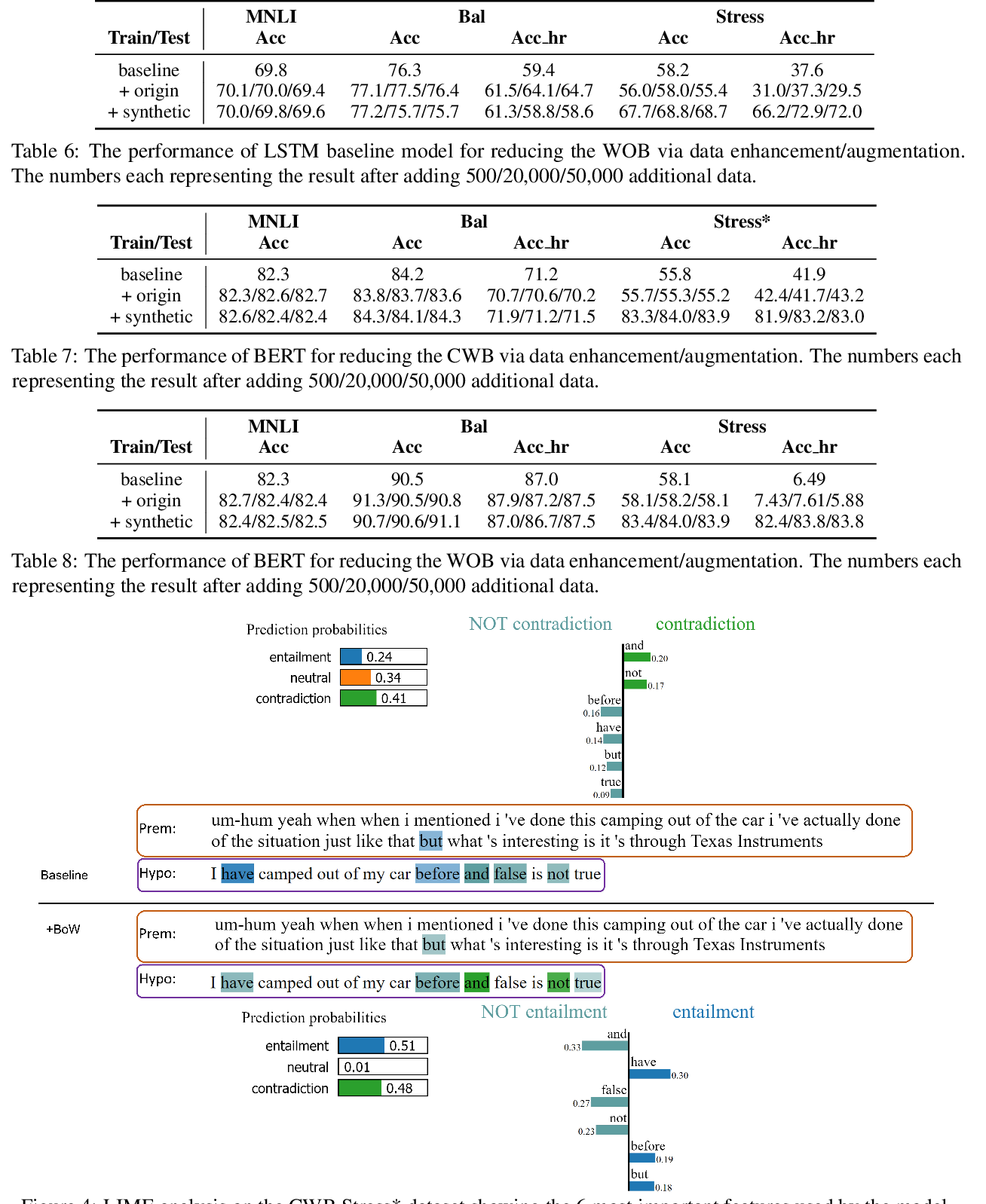
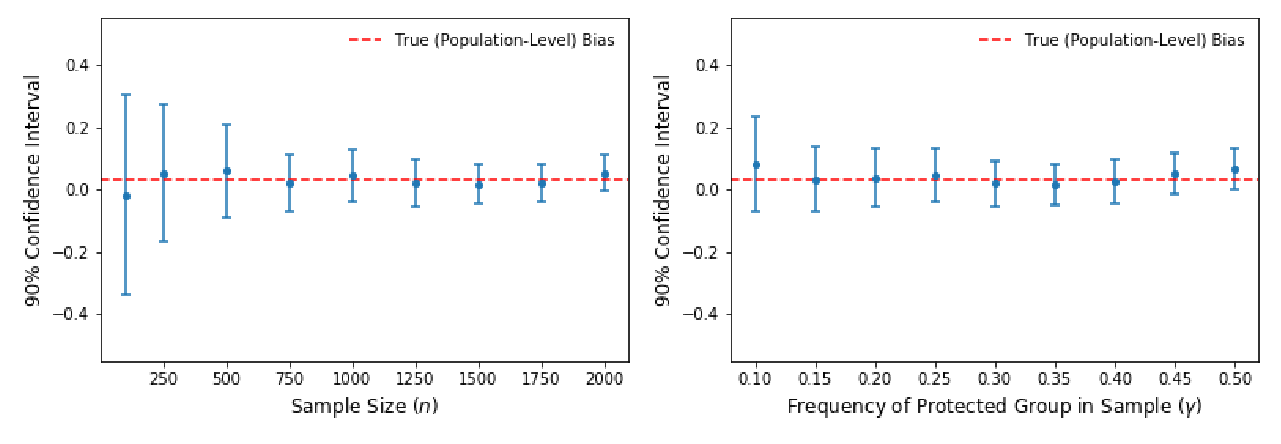
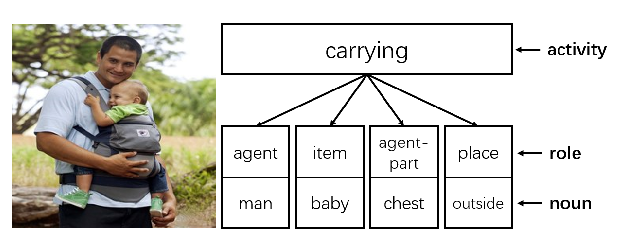
An increasing number of natural language processing papers address the effect of bias on predictions, introducing mitigation techniques at different parts of the standard NLP pipeline (data and models). However, these works have been conducted individually, without a unifying framework to organize efforts within the field. This situation leads to repetitive approaches, and focuses overly on bias symptoms/effects, rather than on their origins, which could limit the development of effective countermeasures. In this paper, we propose a unifying predictive bias framework for NLP. We summarize the NLP literature and suggest general mathematical definitions of predictive bias. We differentiate two consequences of bias: outcome disparities and error disparities, as well as four potential origins of biases: label bias, selection bias, model overamplification, and semantic bias. Our framework serves as an overview of predictive bias in NLP, integrating existing work into a single structure, and providing a conceptual baseline for improved frameworks.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Mitigating Gender Bias Amplification in Distribution by Posterior Regularization
Shengyu Jia, Tao Meng, Jieyu Zhao, Kai-Wei Chang,
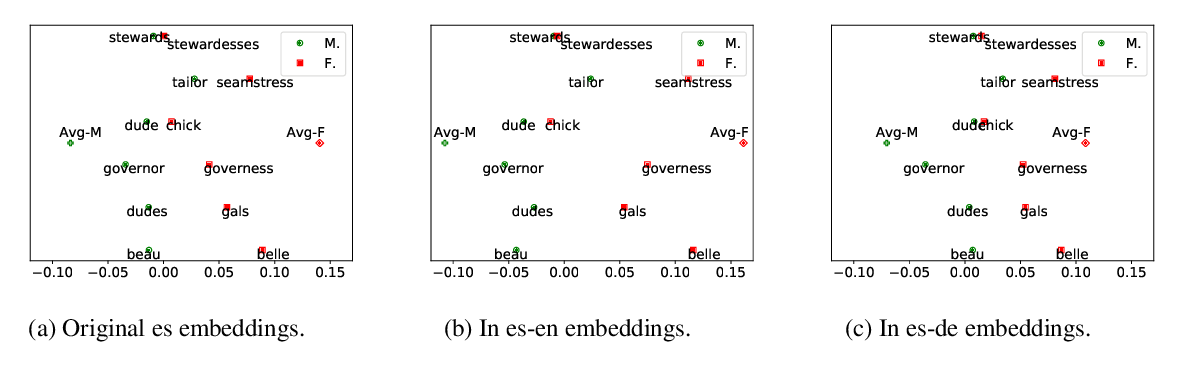
Gender Bias in Multilingual Embeddings and Cross-Lingual Transfer
Jieyu Zhao, Subhabrata Mukherjee, Saghar Hosseini, Kai-Wei Chang, Ahmed Hassan Awadallah,