Text Classification with Negative Supervision
Sora Ohashi, Junya Takayama, Tomoyuki Kajiwara, Chenhui Chu, Yuki Arase
Information Retrieval and Text Mining Short Paper
Session 1A: Jul 6
(05:00-06:00 GMT)

Session 2A: Jul 6
(08:00-09:00 GMT)
Abstract:
Advanced pre-trained models for text representation have achieved state-of-the-art performance on various text classification tasks. However, the discrepancy between the semantic similarity of texts and labelling standards affects classifiers, i.e. leading to lower performance in cases where classifiers should assign different labels to semantically similar texts. To address this problem, we propose a simple multitask learning model that uses negative supervision. Specifically, our model encourages texts with different labels to have distinct representations. Comprehensive experiments show that our model outperforms the state-of-the-art pre-trained model on both single- and multi-label classifications, sentence and document classifications, and classifications in three different languages.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
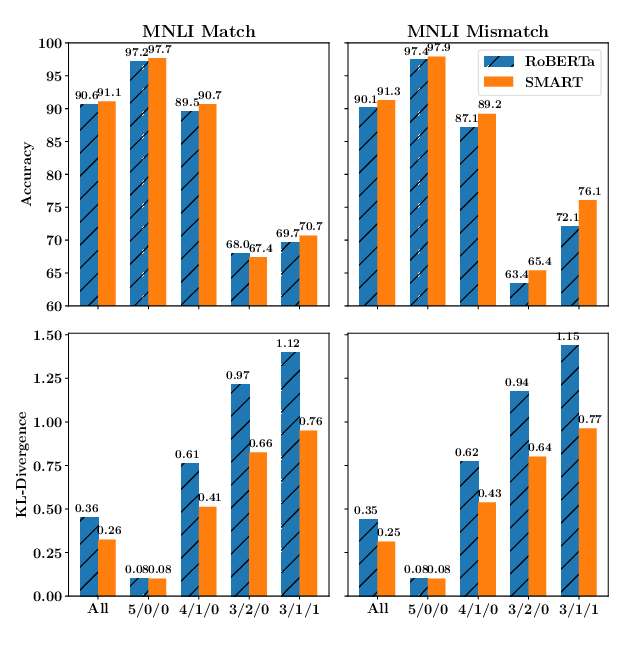
SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization
Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, Tuo Zhao,
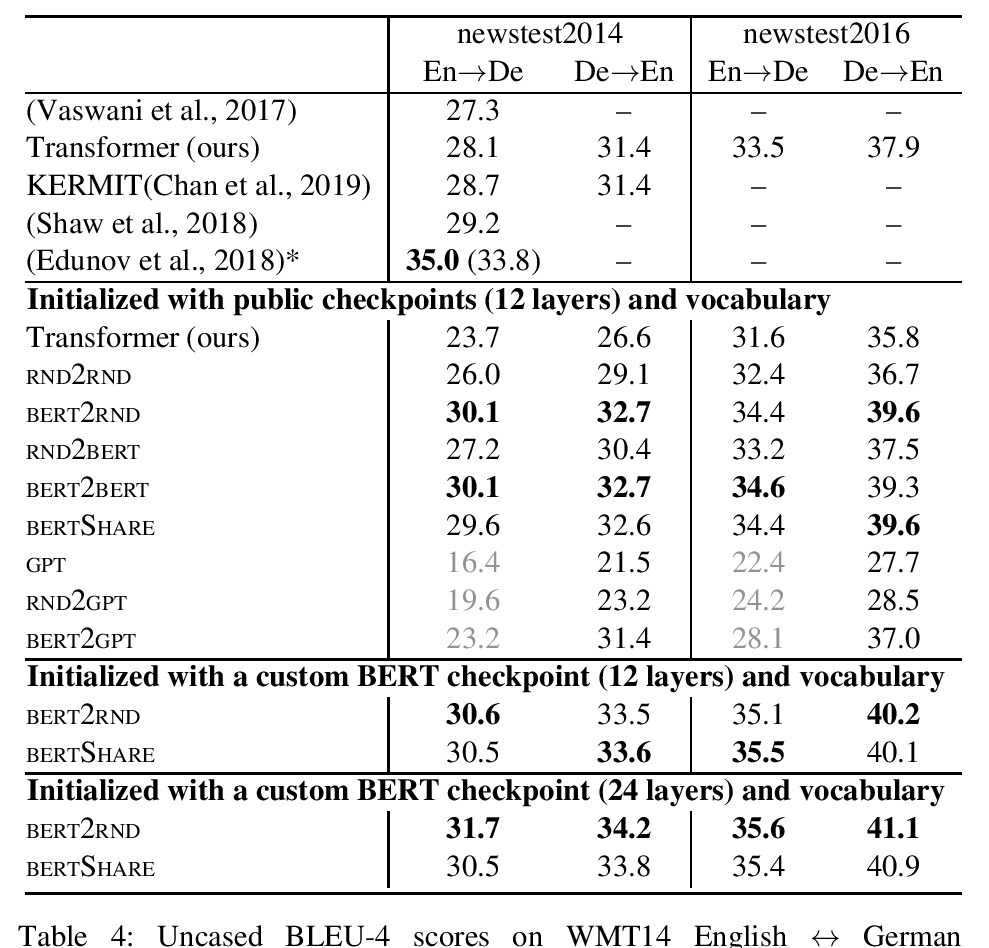
Leveraging Pre-trained Checkpoints for Sequence Generation Tasks
Sascha Rothe, Shashi Narayan and Aliaksei Severyn,
SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis
Hao Tian, Can Gao, Xinyan Xiao, Hao Liu, Bolei He, Hua Wu, Haifeng Wang, Feng Wu,
