Curriculum Pre-training for End-to-End Speech Translation
Chengyi Wang, Yu Wu, Shujie Liu, Ming Zhou, Zhenglu Yang
Speech and Multimodality Long Paper
Session 6B: Jul 7
(06:00-07:00 GMT)

Session 7B: Jul 7
(09:00-10:00 GMT)
Abstract:
End-to-end speech translation poses a heavy burden on the encoder because it has to transcribe, understand, and learn cross-lingual semantics simultaneously. To obtain a powerful encoder, traditional methods pre-train it on ASR data to capture speech features. However, we argue that pre-training the encoder only through simple speech recognition is not enough, and high-level linguistic knowledge should be considered. Inspired by this, we propose a curriculum pre-training method that includes an elementary course for transcription learning and two advanced courses for understanding the utterance and mapping words in two languages. The difficulty of these courses is gradually increasing. Experiments show that our curriculum pre-training method leads to significant improvements on En-De and En-Fr speech translation benchmarks.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
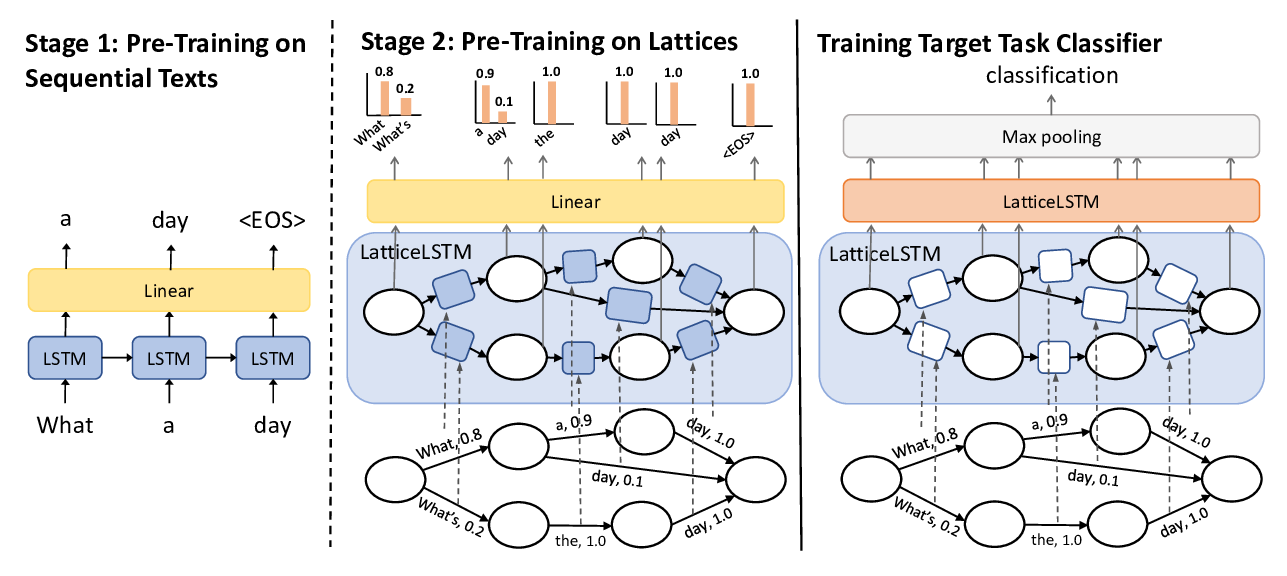
Learning Spoken Language Representations with Neural Lattice Language Modeling
Chao-Wei Huang, Yun-Nung Chen,
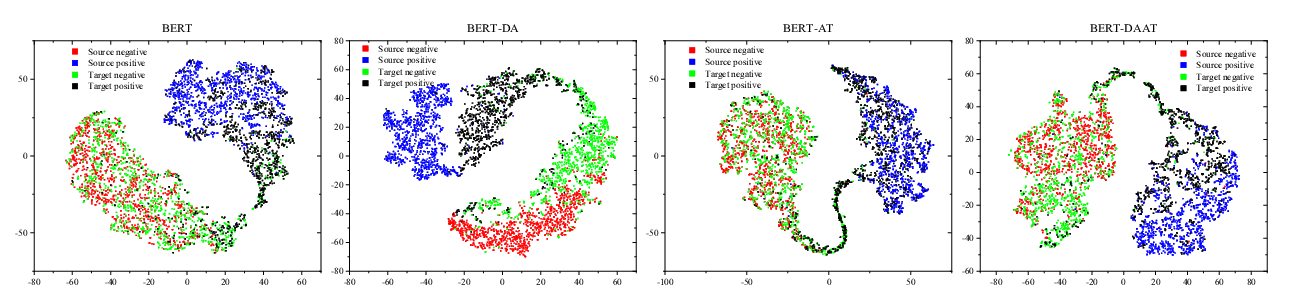
Adversarial and Domain-Aware BERT for Cross-Domain Sentiment Analysis
Chunning Du, Haifeng Sun, Jingyu Wang, Qi Qi, Jianxin Liao,
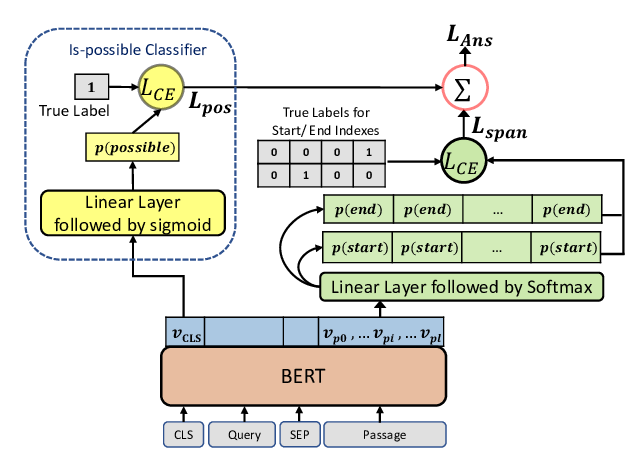
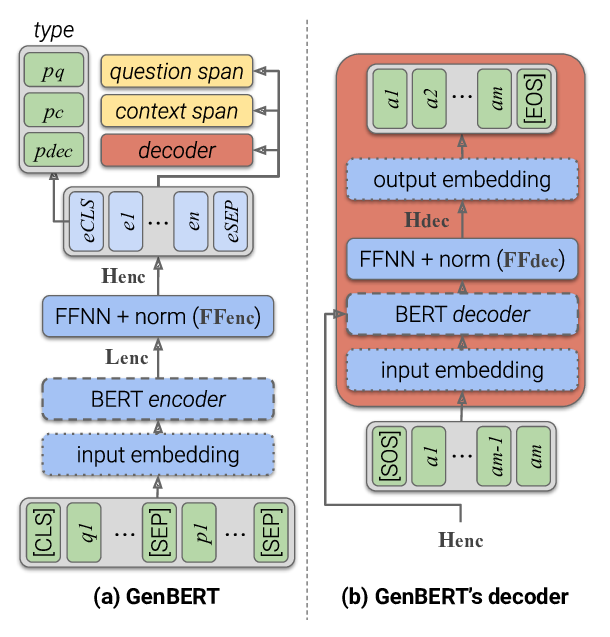
Span Selection Pre-training for Question Answering
Michael Glass, Alfio Gliozzo, Rishav Chakravarti, Anthony Ferritto, Lin Pan, G P Shrivatsa Bhargav, Dinesh Garg, Avi Sil,