Video-Grounded Dialogues with Pretrained Generation Language Models
Hung Le, Steven C.H. Hoi
Dialogue and Interactive Systems Short Paper
Session 11A: Jul 8
(05:00-06:00 GMT)

Session 12B: Jul 8
(09:00-10:00 GMT)
Abstract:
Pre-trained language models have shown remarkable success in improving various downstream NLP tasks due to their ability to capture dependencies in textual data and generate natural responses. In this paper, we leverage the power of pre-trained language models for improving video-grounded dialogue, which is very challenging and involves complex features of different dynamics: (1) Video features which can extend across both spatial and temporal dimensions; and (2) Dialogue features which involve semantic dependencies over multiple dialogue turns. We propose a framework by extending GPT-2 models to tackle these challenges by formulating video-grounded dialogue tasks as a sequence-to-sequence task, combining both visual and textual representation into a structured sequence, and fine-tuning a large pre-trained GPT-2 network. Our framework allows fine-tuning language models to capture dependencies across multiple modalities over different levels of information: spatio-temporal level in video and token-sentence level in dialogue context. We achieve promising improvement on the Audio-Visual Scene-Aware Dialogues (AVSD) benchmark from DSTC7, which supports a potential direction in this line of research.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization
Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, Tuo Zhao,
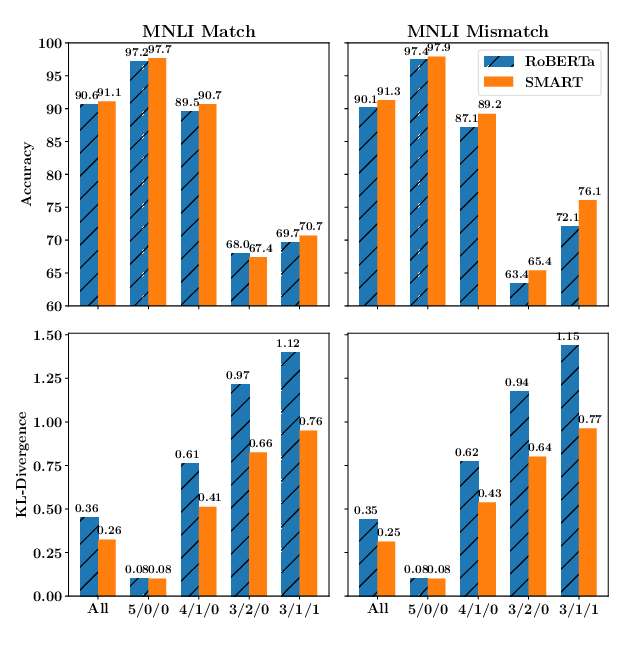
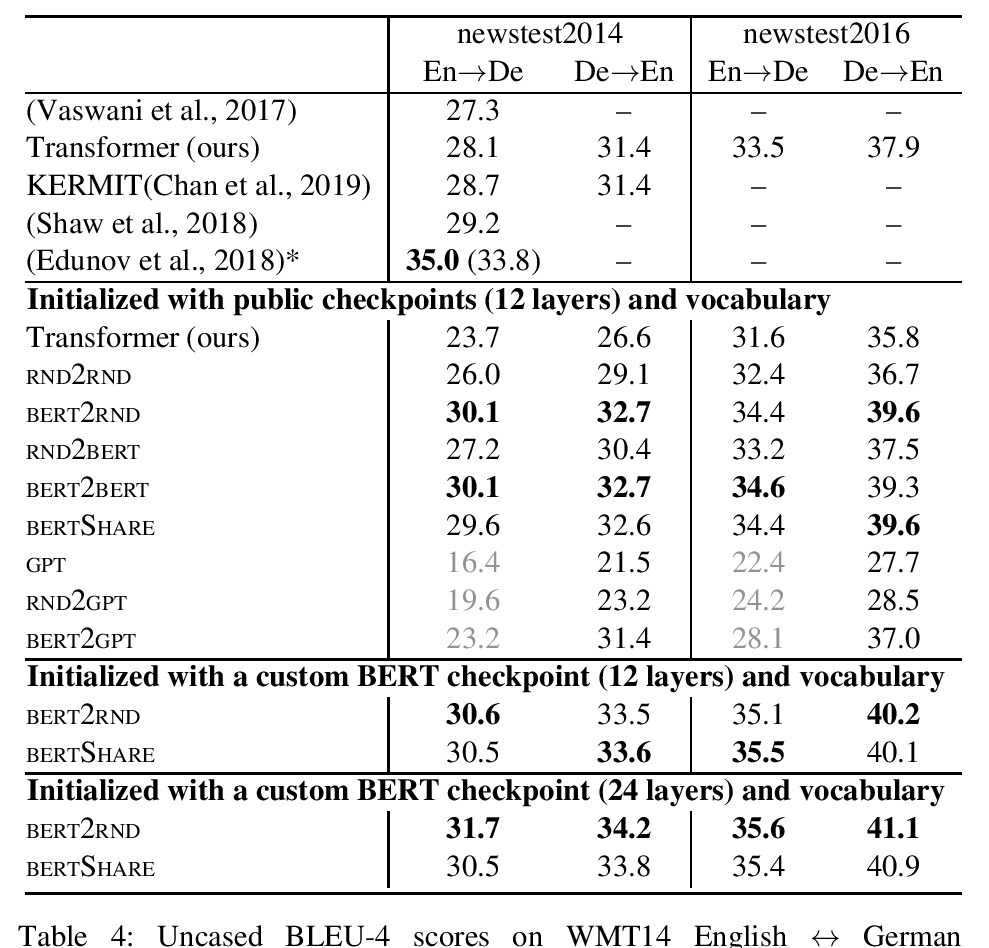
Leveraging Pre-trained Checkpoints for Sequence Generation Tasks
Sascha Rothe, Shashi Narayan and Aliaksei Severyn,
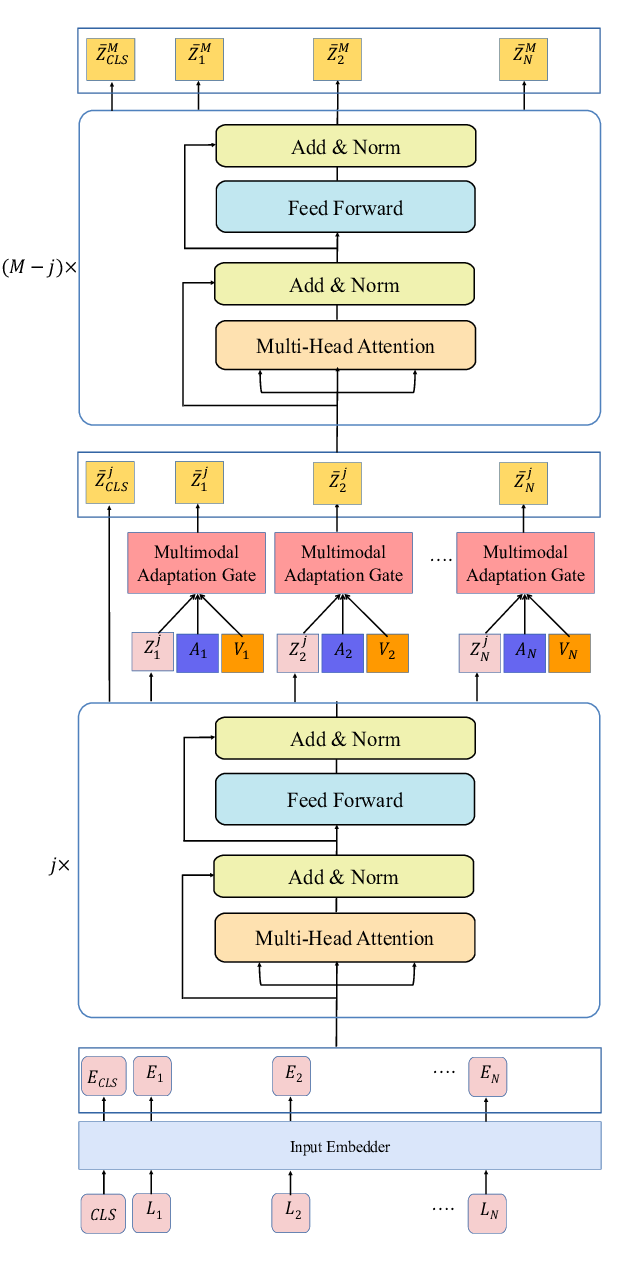
Integrating Multimodal Information in Large Pretrained Transformers
Wasifur Rahman, Md Kamrul Hasan, Sangwu Lee, AmirAli Bagher Zadeh, Chengfeng Mao, Louis-Philippe Morency, Ehsan Hoque,
DIALOGPT : Large-Scale Generative Pre-training for Conversational Response Generation
Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan,