2kenize: Tying Subword Sequences for Chinese Script Conversion
- Pranav A, Isabelle Augenstein
Phonology, Morphology and Word Segmentation Long Paper
Session 12B: Jul 8
(09:00-10:00 GMT)

Session 13B: Jul 8
(13:00-14:00 GMT)
Abstract:
Simplified Chinese to Traditional Chinese character conversion is a common preprocessing step in Chinese NLP. Despite this, current approaches have insufficient performance because they do not take into account that a simplified Chinese character can correspond to multiple traditional characters. Here, we propose a model that can disambiguate between mappings and convert between the two scripts. The model is based on subword segmentation, two language models, as well as a method for mapping between subword sequences. We further construct benchmark datasets for topic classification and script conversion. Our proposed method outperforms previous Chinese Character conversion approaches by 6 points in accuracy. These results are further confirmed in a downstream application, where 2kenize is used to convert pretraining dataset for topic classification. An error analysis reveals that our method's particular strengths are in dealing with code mixing and named entities.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
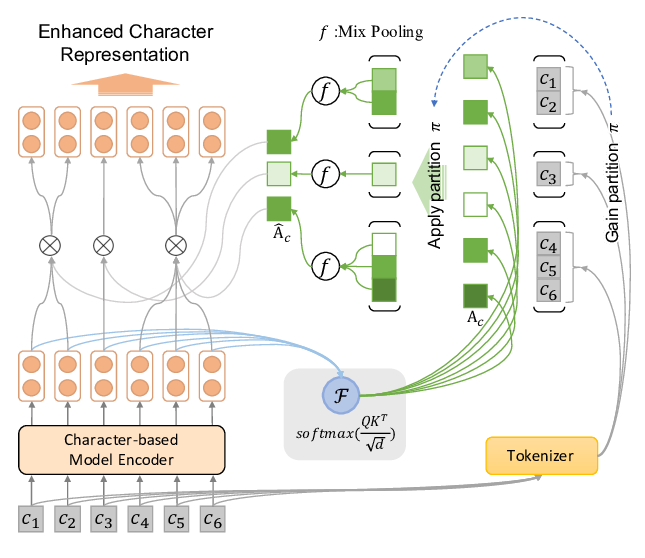
Enhancing Pre-trained Chinese Character Representation with Word-aligned Attention
Yanzeng Li, Bowen Yu, Xue Mengge, Tingwen Liu,
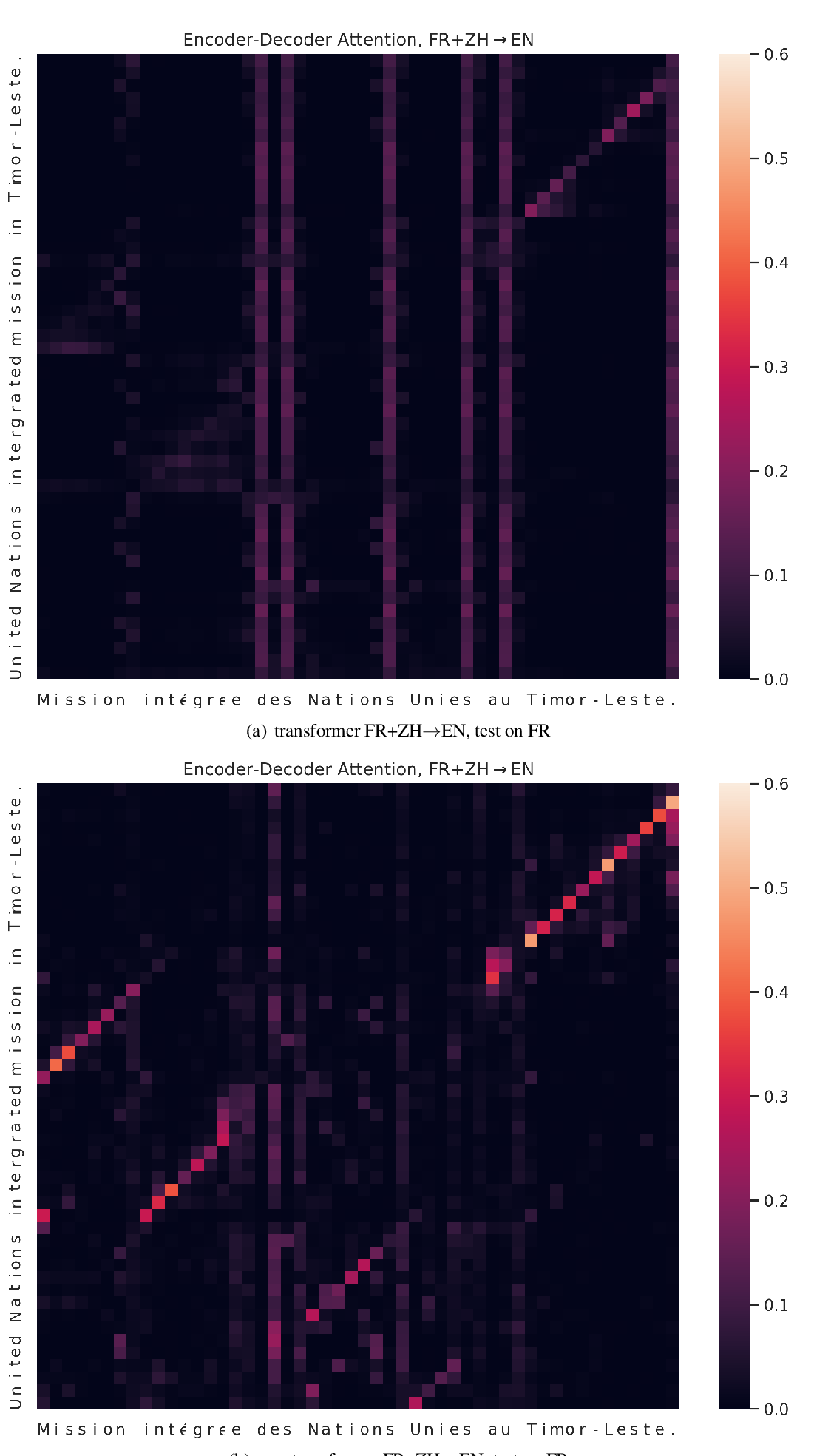
Character-Level Translation with Self-attention
Yingqiang Gao, Nikola I. Nikolov, Yuhuang Hu, Richard H.R. Hahnloser,
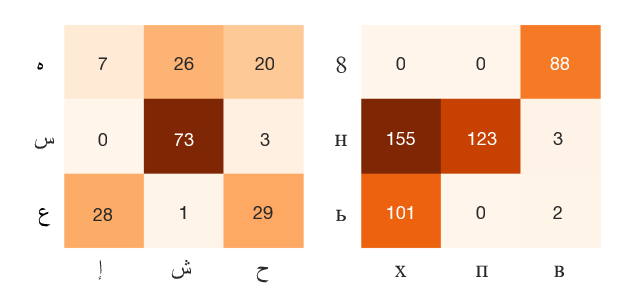
Phonetic and Visual Priors for Decipherment of Informal Romanization
Maria Ryskina, Matthew R. Gormley, Taylor Berg-Kirkpatrick,
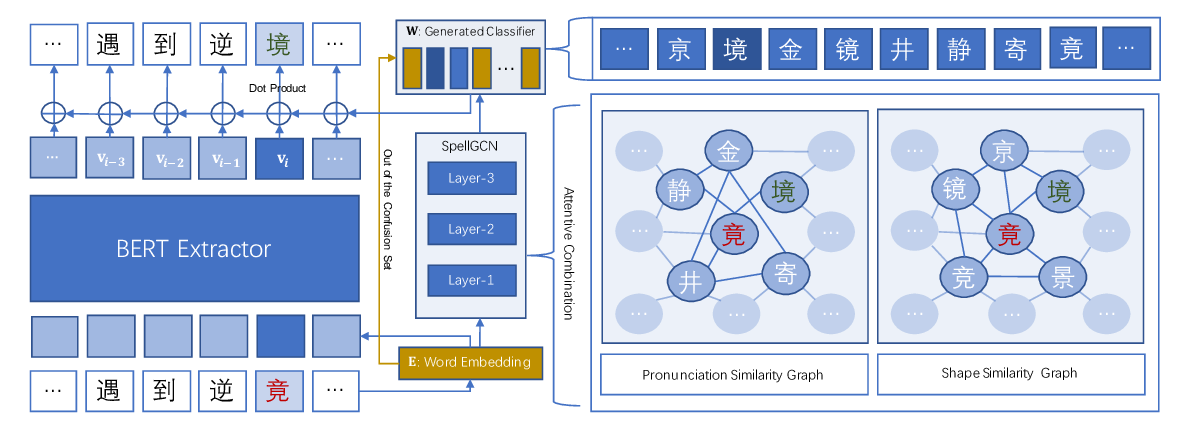
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
Xingyi Cheng, Weidi Xu, Kunlong Chen, Shaohua Jiang, Feng Wang, Taifeng Wang, Wei Chu, Yuan Qi,