Translationese as a Language in "Multilingual" NMT
Parker Riley, Isaac Caswell, Markus Freitag, David Grangier
Machine Translation Long Paper
Session 13B: Jul 8
(13:00-14:00 GMT)

Session 15B: Jul 8
(21:00-22:00 GMT)
Abstract:
Machine translation has an undesirable propensity to produce ``translationese" artifacts, which can lead to higher BLEU scores while being liked less by human raters. Motivated by this, we model translationese and original (i.e. natural) text as separate languages in a multilingual model, and pose the question: can we perform zero-shot translation between original source text and original target text? There is no data with original source and original target, so we train a sentence-level classifier to distinguish translationese from original target text, and use this classifier to tag the training data for an NMT model. Using this technique we bias the model to produce more natural outputs at test time, yielding gains in human evaluation scores on both accuracy and fluency. Additionally, we demonstrate that it is possible to bias the model to produce translationese and game the BLEU score, increasing it while decreasing human-rated quality. We analyze these outputs using metrics measuring the degree of translationese, and present an analysis of the volatility of heuristic-based train-data tagging.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
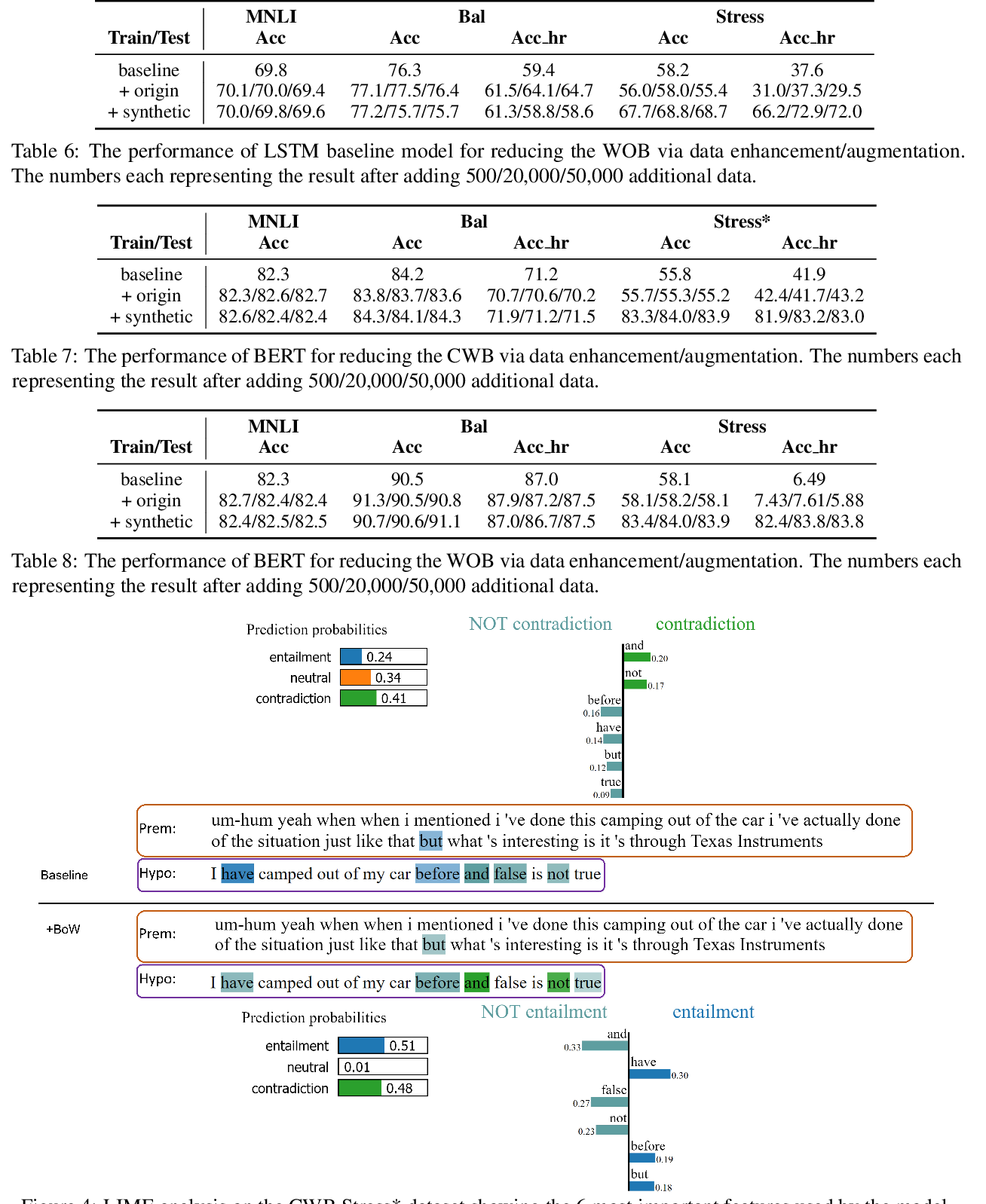
On The Evaluation of Machine Translation SystemsTrained With Back-Translation
Sergey Edunov, Myle Ott, Marc'Aurelio Ranzato, Michael Auli,

Tagged Back-translation Revisited: Why Does It Really Work?
Benjamin Marie, Raphael Rubino, Atsushi Fujita,
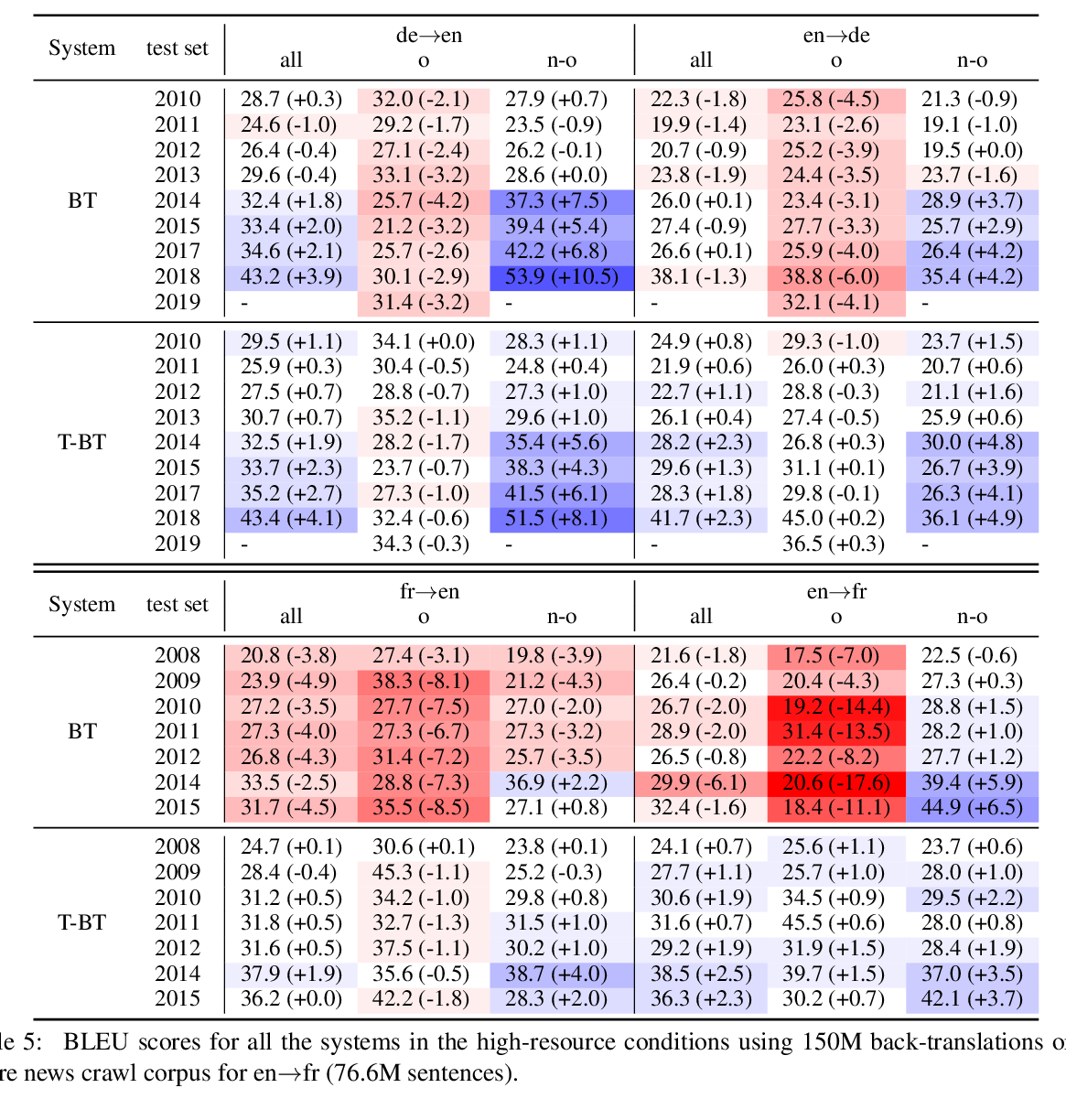
Reducing Gender Bias in Neural Machine Translation as a Domain Adaptation Problem
Danielle Saunders, Bill Byrne,