Estimating Mutual Information Between Dense Word Embeddings
Vitalii Zhelezniak, Aleksandar Savkov, Nils Hammerla
Semantics: Sentence Level Short Paper
Session 14A: Jul 8
(17:00-18:00 GMT)

Session 15A: Jul 8
(20:00-21:00 GMT)
Abstract:
Word embedding-based similarity measures are currently among the top-performing methods on unsupervised semantic textual similarity (STS) tasks. Recent work has increasingly adopted a statistical view on these embeddings, with some of the top approaches being essentially various correlations (which include the famous cosine similarity). Another excellent candidate for a similarity measure is mutual information (MI), which can capture arbitrary dependencies between the variables and has a simple and intuitive expression. Unfortunately, its use in the context of dense word embeddings has so far been avoided due to difficulties with estimating MI for continuous data. In this work we go through a vast literature on estimating MI in such cases and single out the most promising methods, yielding a simple and elegant similarity measure for word embeddings. We show that mutual information is a viable alternative to correlations, gives an excellent signal that correlates well with human judgements of similarity and rivals existing state-of-the-art unsupervised methods.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
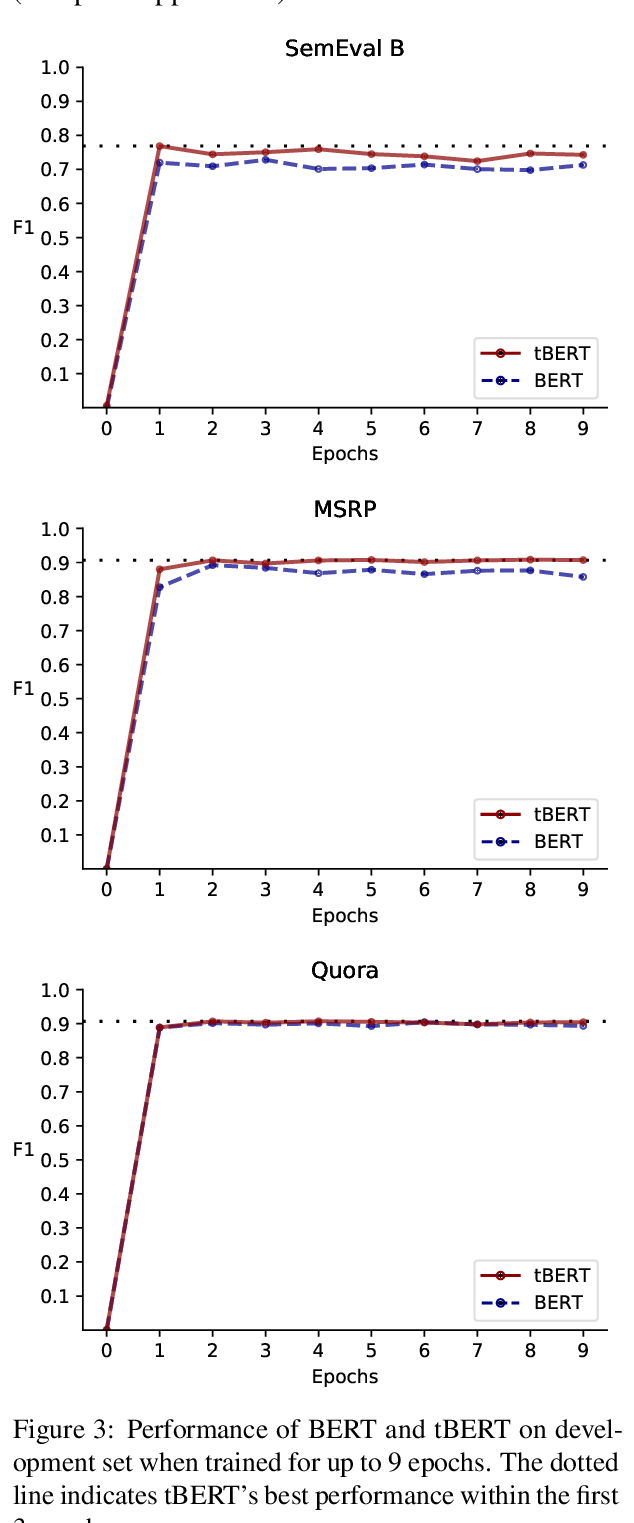
tBERT: Topic Models and BERT Joining Forces for Semantic Similarity Detection
Nicole Peinelt, Dong Nguyen, Maria Liakata,
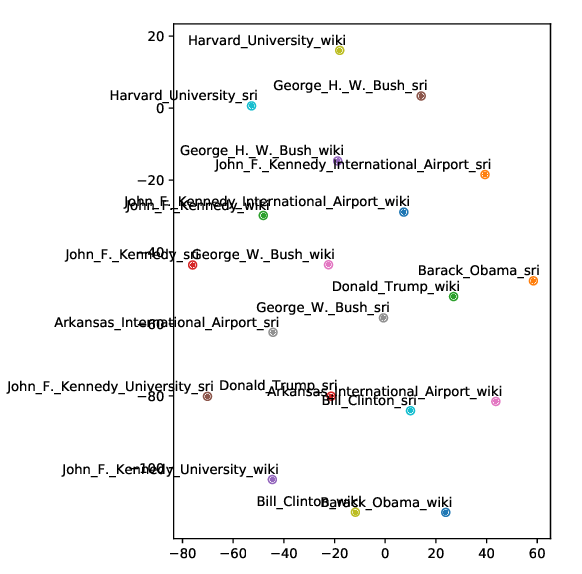
Improving Entity Linking through Semantic Reinforced Entity Embeddings
Feng Hou, Ruili Wang, Jun He, Yi Zhou,
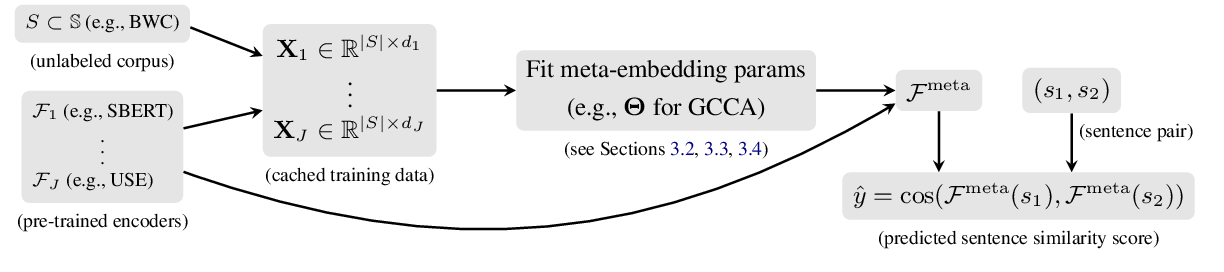
Sentence Meta-Embeddings for Unsupervised Semantic Textual Similarity
Nina Poerner, Ulli Waltinger, Hinrich Schütze,
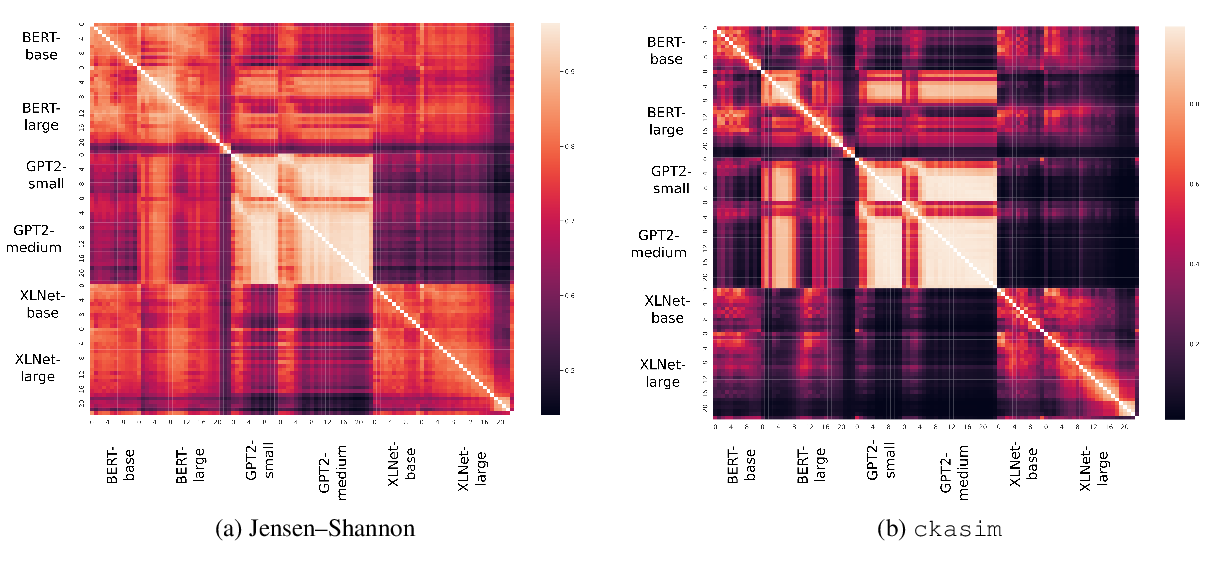
Similarity Analysis of Contextual Word Representation Models
John Wu, Yonatan Belinkov, Hassan Sajjad, Nadir Durrani, Fahim Dalvi, James Glass,