Treebank Embedding Vectors for Out-of-domain Dependency Parsing
Joachim Wagner, James Barry, Jennifer Foster
Syntax: Tagging, Chunking and Parsing Short Paper
Session 14B: Jul 8
(18:00-19:00 GMT)

Session 15B: Jul 8
(21:00-22:00 GMT)
Abstract:
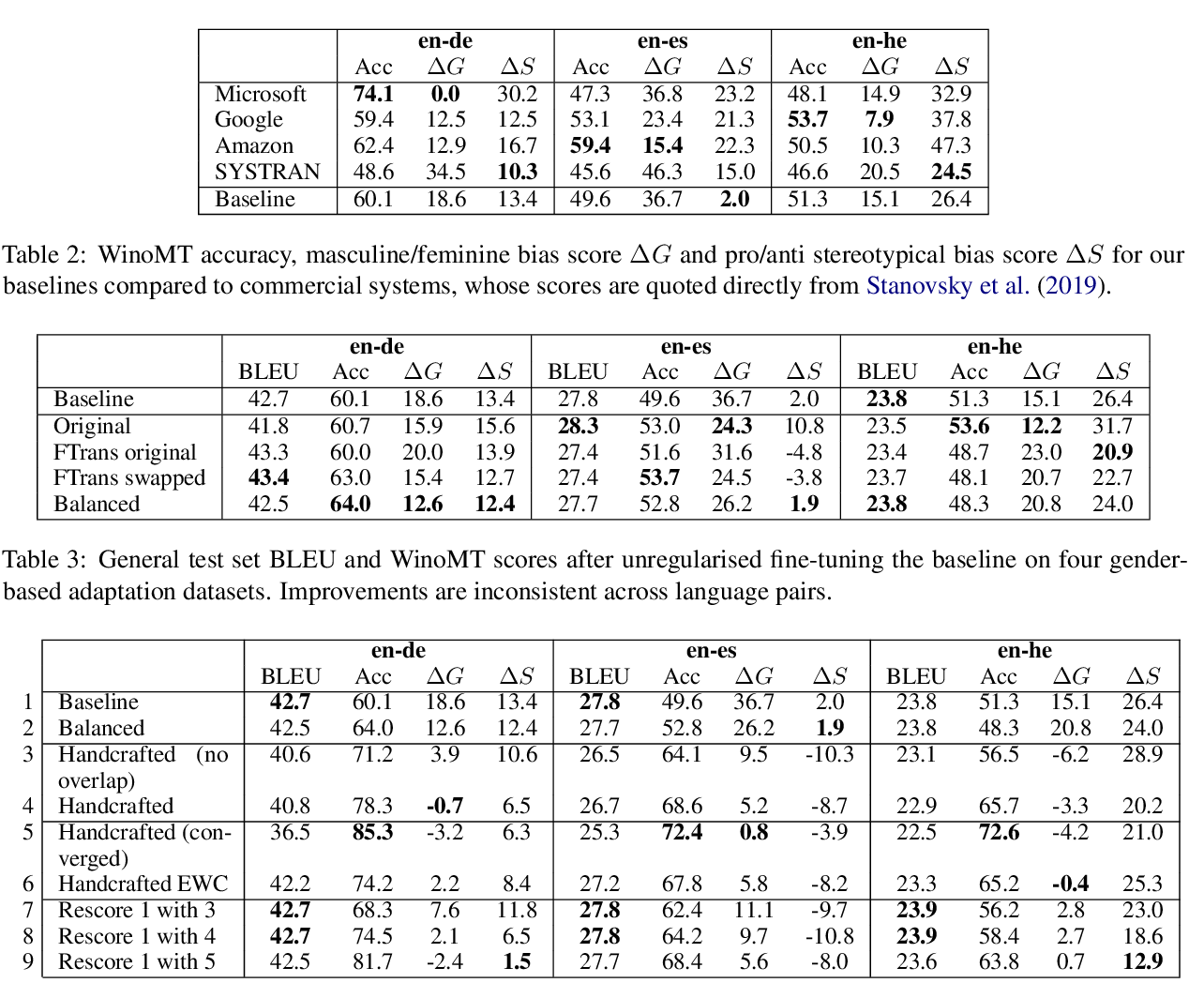
A recent advance in monolingual dependency parsing is the idea of a treebank embedding vector, which allows all treebanks for a particular language to be used as training data while at the same time allowing the model to prefer training data from one treebank over others and to select the preferred treebank at test time. We build on this idea by 1) introducing a method to predict a treebank vector for sentences that do not come from a treebank used in training, and 2) exploring what happens when we move away from predefined treebank embedding vectors during test time and instead devise tailored interpolations. We show that 1) there are interpolated vectors that are superior to the predefined ones, and 2) treebank vectors can be predicted with sufficient accuracy, for nine out of ten test languages, to match the performance of an oracle approach that knows the most suitable predefined treebank embedding for the test set.
You can open the
pre-recorded video
in a separate window.
NOTE: The SlidesLive video may display a random order of the authors.
The correct author list is shown at the top of this webpage.
Similar Papers
Exploiting Syntactic Structure for Better Language Modeling: A Syntactic Distance Approach
Wenyu Du, Zhouhan Lin, Yikang Shen, Timothy J. O'Donnell, Yoshua Bengio, Yue Zhang,
Efficient Contextual Representation Learning With Continuous Outputs
Liunian Harold Li, Patrick H. Chen, Cho-Jui Hsieh, Kai-Wei Chang,

Stolen Probability: A Structural Weakness of Neural Language Models
David Demeter, Gregory Kimmel, Doug Downey,
Reducing Gender Bias in Neural Machine Translation as a Domain Adaptation Problem
Danielle Saunders, Bill Byrne,